



导读
GPT 出现之后,很多人推测大量的软件都会因为其出现而重写。本文主要是低代码平台与 ChatGPT 结合的一些思考以及实践。期望与各位读者一起搭上 AI 这列快车,为开发提提速~
目录
1 背景
2 Demo 演示
3 思路
3.1 ChatGPT+代码生成工具结合模式
3.2 ChatGPT 代码生成现状
3.3 现阶段可行的思路
3.4 案例
4 设计实现
4.1 架构分层
4.2 插件化
4.3 研发调整
5 总结
01
背景
从探索模型驱动开发开始,我一直在思考一个问题:“软件,是否可以用更简单、更人性化的方式生成”,ChatGPT 给我了一个肯定的回答。
我们此前根据领域模型在生成代码方面进行了一些探索,希望用建模时间高倍率置换编码时间。随着代码工具的不断完善,效率提升越来越难,因为模型是抽象的而实现是具体的,模型所承载的信息并不足以直接生成代码,一定需要“人”来补充信息,这部分工作工具无法替“人”来完成。
直到体验了 ChatGPT,在震惊于它强大的能力同时,我们也就“如何将 ChatGPT 引入我们的代码生成工具来提升研发效能”进行了思考,并且快速搭建了一些 Demo 验证效果。
02
Demo 演示
“Talk is cheap. Show me the code”,
视频中类图、分析序列图来源于 UMLChina
这里演示了工具基于领域模型生成代码的流程,在第3到5步工具集成了一个基于 ChatGPT 接口实现的插件,该插件自动提取模型中的中文类名、成员变量名、成员函数中文名,然后将中文名以及翻译用途、命名风格输入到 ChatGPT 得到翻译结果,并自动填充回工具,最后生成代码。
这里仅仅是简单地使用了 ChatGPT 的翻译能力,却给我们带来了巨大的提升,想象一下一个项目数十个类名、数百个成员变量名以及函数名需要根据中文翻译为英文,有些词还要使用翻译软件翻译后再根据使用用途(类名使用名词或者名词短语、方法名使用动词)转换词性,然后调整为大驼峰或者下划线连接等风格,这是多么无趣和繁琐的工作,而现在只需要一键填充,然后做微小调整即可。
仅接入了 ChatGPT 的翻译能力就提效如此明显,那如果将 ChatGPT 的能力封装为一个一个插件嵌入到整个研发过程,那会达到什么效果呢?
03
思路
3.1 ChatGPT+代码生成工具结合模式
3.1.1 模式一:直接生成软件
这种模式让 ChatGPT 理解人类语言并编写软件,例如 ChatGPT 完全可以生成一个可运行的贪吃蛇小游戏,当然严格意义上这种模式并不是 ChatGPT 和代码生成工具结合,因为根本不需要代码生成工具参与,这无疑是最简单、最自然的软件开发方式。
遗憾的是通过测试发现:ChatGPT 现阶段并不能直接通过对话编写出完整的、复杂的软件,因为软件有自己的核心域知识,而且不同的团队都有自己的规范、环境等要求,例如谷歌使用 gRPC 框架、部署在谷歌云,而亚马逊的研发框架和部署环境与谷歌完全不同。我们不可能将这些信息全部输入到 ChatGPT(这些信息太多了,通过会话描述这些信息需要大量的工作,除了考虑性能以外也担心敏感信息泄露问题)。现阶段该模式无法实现。我想,尽管 AutoGPT 的出现说明 AI 确实可以从0到1完成一个项目,但我想没有人敢将它生成的项目直接应用于生产环境。
3.1.2 模式二:生成代码片段
通过会话将代码上下文信息输入到 ChatGPT,它基于这些信息完善、编辑代码,例如 Copilot 插件就是该模式。测试发现 ChatGPT 生成代码片段的质量比较高且比较稳定。
该模式和模式一的区别是代码是“工具”将 ChatGPT 生成的“代码片段”进行组织,最终形成完整的软件。
3.1.3 模式三:生成DSL
将自然语言转换为 DSL ,然后基于 DSL 生成代码或者软件,这种模式和方案二的区别是 ChatGPT 不直接生成代码,代码是由工具根据 ChatGPT 生成的 DSL 生成。ChatGPT 生成 DSL 相对稳定,这种模式生成的代码质量相对前两种模式更加可靠。
3.2 ChatGPT 代码生成现状
“知彼知己,百战不殆”,我们首先要对 ChatGPT 的能力有个清晰认识,这样才能选择正确的模式。我们阅读了一些 GPT-4 能力测评论文,也做了大量的实验验证,说几个有意思的点:
| ChatGPT 是“懂”代码的,给出一段代码可以正确的添加注释,甚至还可以根据上下文优化变量命名、完善代码;ChatGPT 是会“猜”代码的,仅仅给出一个函数声明,它可以根据函数命名、参数命名猜测函数的功能,并生成测试用例;ChatGPT 生成通用代码(例如基础库)比较容易,但是生成特定领域的代码可能不符合该领域的最佳实践;ChatGPT 生成代码质量和使用者有关,输入越准确生成代码质量越高,输入内容过多或者过少都会导致生成结果变差。 |
在实际场景中我们写代码所依赖的信息非常多,除了当前文件的上下文还可能跨文件、跨系统、跨仓库……但是由于 ChatGPT 对输入长度的限制,将所有依赖信息输入到 ChatGPT 是不现实的(时间成本、敏感代码泄露);另外一个问题是交互模式,如果代码是离线生成还好,但如果是“和 ChatGPT 结对编程”对实时性要求是非常高的,想象一下如果 Copilot 每次生成提示都需要1分钟你还会用吗?
3.3 现阶段可行的思路
结合上述信息,我们认为尽管目前 GPT4 能力非常强大,但是并不能做到全自动生成应用,尤其是针对某个行业需要匹配该行业的最佳实践和领域知识,需要遵循团队研发规范。这些是 ChatGPT 现阶段所无法做到的。那基于 ChatGPT 现有的能力,如何嵌入到代码生成工具中呢?我作了一些粗浅的思考:
| 利用 ChatGPT 辅助生成 DSL,将 DSL 导入到低代码平台生成符合团队规范的业务代码;将第一步生成的代码输入到 ChatGPT,由 ChatGPT 根据上下文补充生成代码片段并填充到对应位置; |
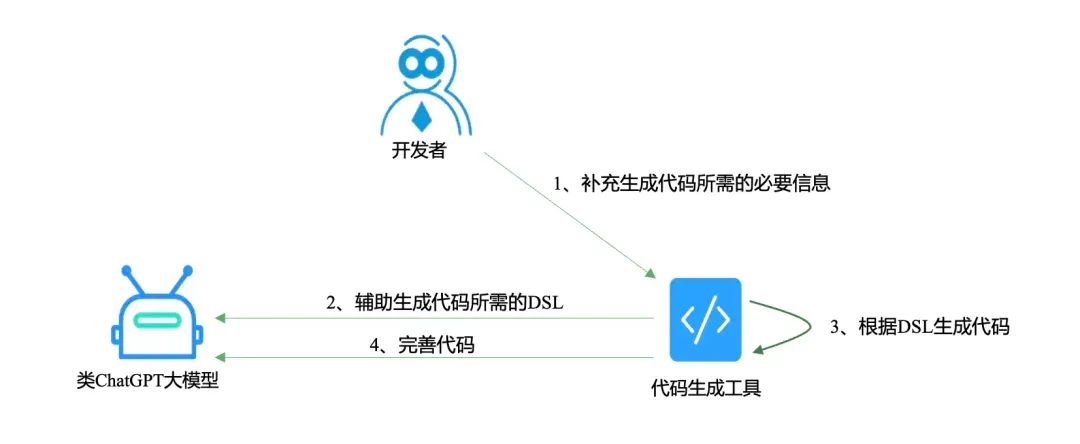
读到这里也许会有疑问,这明显就是模式二和模式三的结合,为什么要分两次让 ChatGPT 生成代码呢?我下面用一个案例进行详细解释。
3.4 案例
3.4.1 信息提取

如上图所示,这是系统用例“接收车位状态变化”的分析序列图,通过分析序列图我们可以得到如下信息:
| · 控制类有一个方法为“停车收费”;· 控制类的“停车收费”方法依赖实体类“泊位”;· 分析序列图中的实体类的成员变量可以在类图中得到,所有指向该实体的箭头都映射为一个方法;· 可以根据分析序列图得到控制类和实体类方法的伪代码,例如“来车”的伪代码如下: |
int 泊位::来车(){
// 1、取值班人员
排班(时间).取值班人员(值班人员序号);
if(失败){
打印日志
返回失败错误码
}
return 0
}
3.4.2 构建DSL生成代码
显然上述信息并不足以生成代码,以“泊位::来车”这段伪代码为例,要想映射为一段符合C++语法的代码,至少还需要完善下面这些信息:
| 翻译,伪代码中的单词都要翻译为英文;补充字段类型,时间字段是什么类型;模式配置,例如“取值班人员”方法失败怎么定义?根据返回码判断还是根据某个出参判断; |
做完这些工作后,我们才能将上述伪代码使用结构化的语言描述以便生成代码,例如:
{
"return_type":"int",
"function_name":"ArriveCar",
"param":[],
"impl":[
{
"entity":"Scheduling",
"function":"GetShiftPersonnel",
"return_type":"int",
"param":[
{
"type":"int",
"name":"number"
}
]
}
]
}事实上需要配置的信息远远不止这些,而且完成这些工作的知识都在“人脑”中,只能人来完成, 构建可以生成的代码的 DSL 并不简单。当然我们可以通过一些方法来减少人的工作:例如将填空题修改为选择题(大多数配置都是勾选操作而不用输入文字)、总结最佳实践添加默认选择项(例如成员变量默认不生成Get函数)等等,然而始终有一部分工作是繁琐、重复、低效且需要人来完成的,例如上述步骤中的中文根据使用情景不同翻译为不同词性、不同格式的英文单词。而这部分工作就需要引入 ChatGPT 来完成,由人来翻译500个中文词可能需要50分钟(10个/分钟),而让 ChatGPT 来翻译仅需要几秒钟。
3.4.3 完善代码
经过第一步从模型提取信息、第二步将信息转换为生成代码所需要的 DSL ,这时候我们就可以生成代码了,下面是我们生成的代码目录的一个案例:
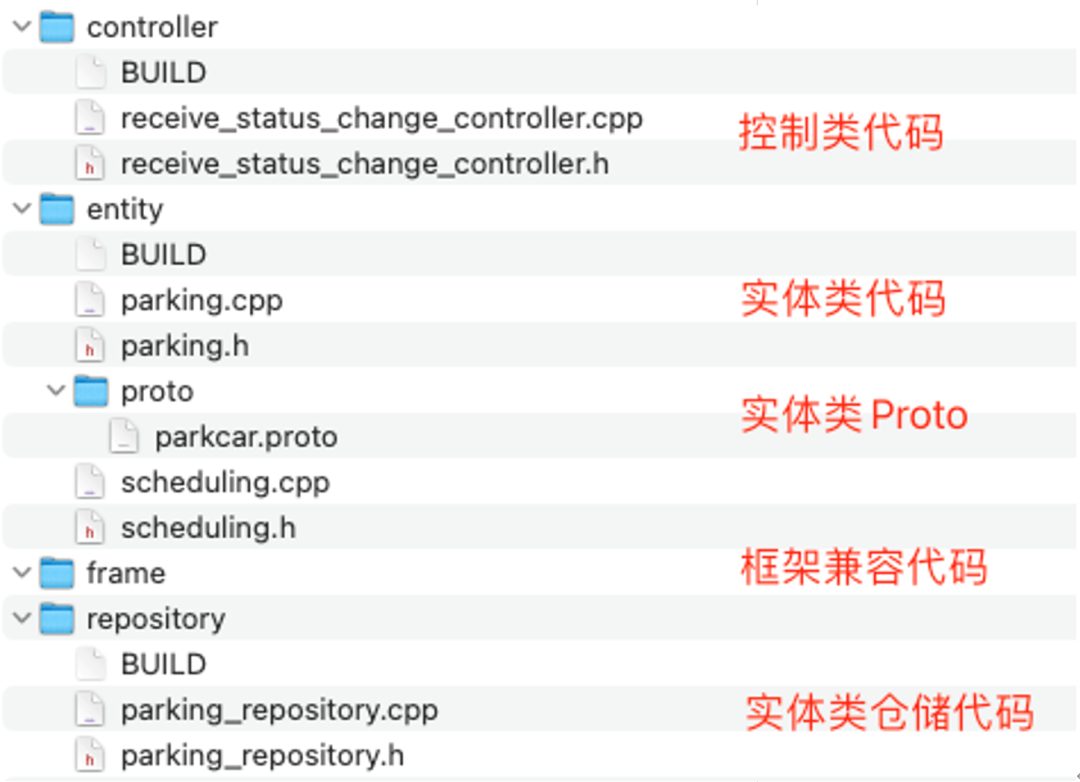
我们打开上述目录中的头文件、PROTO 文件不仅满意的点了点头。但当我们点开泊车类的 .cpp 文件见到下面内容不仅吐槽:生成的代码并不能直接运行!
// 来车
int ParkingSpace::ArriveCar() {
//// MDD-TAG-BEGIN:[flow][slot-ArriveCar][函数实现]
int ret = 0;
// 取值班人员
Scheduling scheduling (/*请填充参数*/);
ret = scheduling.GetShiftPersonnel(number);
if (ret != 0) {
LOG_VERR("--->>错误事件名<<---", ret, "GetShiftPersonnel_ERR");
return ret;
}
return ret;
//// MDD-TAG-END:[flow][slot-ArriveCar]
}是的,到这一步大部分的方法实现并没有生成。在这里分析一些原因,以上图中的伪代码为例,如果要生成代码需要人补充什么信息呢?
| “排班”实体的构造方法可能有多个,该调用哪个呢?排班实体的“取值班人员”方法中返回0是否就意味着获取成功?参数“number”使用哪里的值填充?使用泊车类的成员变量还是某个全局变量填充?错误日志该打印哪些变量? |
仅仅是这么几行伪代码就需要补充如此多的信息,假如这些信息都是由人来配置,那和直接写代码有什么区别呢?IDE 通过友好的提示,直接写代码甚至比在工具配置后生成代码效率更高!所幸的是,无需人工配置,只要我们将伪代码转换为业务代码所需要的头文件定义等输入到 ChatGPT,它就可以自动推导实现,生成代码。这就是为什么要“分两次让 ChatGPT 生成代码”。第一次是生成 DSL 以便代码生成工具生成质量有保证的代码框架、头文件定义等,第二次是根据已经生成的代码继续完善业务代码。思路已经很明确,要想落实为具体方案,那就需要代码生成工具有一个好的设计,这里的好是指“模块化、低耦合、可扩展”,下面介绍代码生成工具的设计实现。
04
设计实现
4.1 架构分层
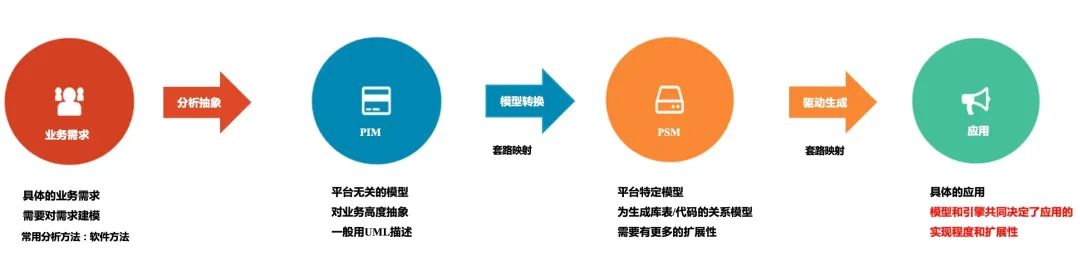
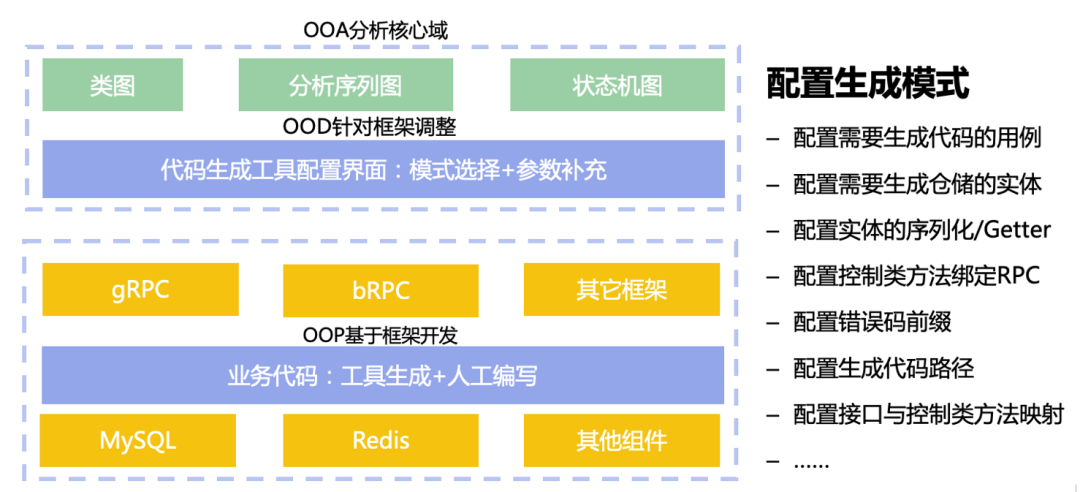
(图源网络)上图中标红的部分“模型和引擎共同决定了应用的实现程度和扩展性”。本文不是讲领域建模的内容,因此建模知识这里不做讨论,我们重点讨论引擎的设计。补充一下系统的架构分层如下:

协议栈: 定义代码生成引擎输入的格式化结构,可以的话这个结构可以作为规范标准供各种低代码平台通用使用,当然如果能够做到这点就能解决掉低无代码平台的互联互通问题(难而正确的事),是对整个行业有利的事情。代码生成引擎:对协议栈的实现,定义了代码生成的模版,将输入的数据进行处理后根据需求填入到不同的模板中,生成 C++、TS 等代码。引擎插件:基于引擎进行拓展,例如使引擎更灵活,支持更多的协议。我们和 ChatGPT 结合实际上就是对 ChatGPT 的能力进行封装,实现为一个个的插件辅助人来完成工作,提高代码生成工具的易用性。代码生成工具: 对引擎以及插件的封装,是面向用户的产品。
4.2 插件化
明确了架构的分层,我们和 ChatGPT 集成的方案也就自然而然地明确了:将模型映射代码的过程拆解为一个一个的任务,分析哪些任务现阶段是由人完成的且 ChatGPT 已经具备相应的能力,则基于 ChatGPT 的能力分装为一个一个的插件,协助人完成相应的任务,提升效能。下面我们讲解对几个插件的思考。
4.2.1 代码生成插件
让 ChatGPT 来生成代码,Prompt 需要包含如下三部分信息:有什么、用什么、做什么。有什么:上文已经解释了我们是让 ChatGPT 生成质量相对稳定的代码片段,即某一个函数的实现。“有什么”实际上就是函数的入参、类的成员变量以及全局变量。入参和类的成员变量可以通过解析领域模型得到,而全局变量则定义在代码生成的模版中,是一些固定的值(一般是全局配置)。用什么:即实现该方法需要哪些实体类方法、边界类方法、基础库。实体类方法在3.4.2展示了,DSL 生成代码后已经有了实体类方法的头文件;边界类方法即对外系统接口的封装,需要进行统一管理,因此也可以很方便地得到。基础库分为官方库和第三方库,官方库无需输入,ChatGPT 可以推导出使用正确的方法,而第三方库由于太多我们暂不处理,我们的目的本来也不是生成100%的代码,无法生成的这部分就交给研发去补充吧(别忘了研发还有 Copilot 等利器)。做什么:需要完善的代码逻辑,就是伪代码,在3.4.3有做展示,这里不再赘述。插件将上述信息拼接为 Prompt ,剩下的就交给 ChatGPT 吧,例如上述泊位::来车方法最终由 ChatGPT 完善为:
// 来车
int ParkingSpace::ArriveCar() {
//// MDD-TAG-BEGIN:[flow][slot-ArriveCar][函数实现]
int ret = 0;
// 取值班人员
Scheduling scheduling (time(nullptr));
ret = scheduling.GetAttendant(number_);
if (ret != 0) {
LOG_VERR("GetAttendant", ret, number_);
return ret;
}
return ret;
//// MDD-TAG-END:[flow][slot-ArriveCar]
}4.2.2 翻译插件
正如第二章所演示的效果,这个插件我们已经实现完成了。目前大多数建模工具支持填写英文名称,但是英文名称为非必填字段且大多数人不习惯使用英文建模,我们提取模型中未关联英文单词的中文,拼接为 Prompt 调用 ChatGPT 统一翻译,一键填充。当然我们所需要的插件不仅仅这两个,我们也脑爆了单测生成插件、SQL 生成插件等等一系列的提效插件。
4.3 研发调整
我们评估如果按照这样的思路,实现代码生成工具可以节省90%以上的工作量,大约剩下的10%是如下工作:代码走查:上面已经说了 ChatGPT 生成的代码只是相对稳定,因此生成的代码默认使用/*和*/包裹注释掉,必须经过研发确认代码正确且调整完毕后才可以删除注释投入使用。代码完善:ChatGPT 无法生成100%的代码,例如上一个接口产生了一个中间结果缓存起来,该接口会使用,考虑到 ChatGPT 的性能、插件实现的复杂性、OPENAI 接口收费价格等因素,我们不可能把上一个接口的信息拼接到Prompt 。这部分逻辑研发直接编写代码所付出的成本远远低于使用 ChatGPT 所需成本。单元测试:ChatGPT 写单元测试的质量远远超出我的想象,它会考虑边界条件等等各种因素,如果是针对基础库生成的测试用例代码几乎不需要修改就可以直接使用,但是如果是控制类等业务代码的测试用例却不能使用,例如上述接口中的 JScode 是小程序产生,毫无疑问 ChatGPT 无法构造出这样的参数,是 Mock 还是调用可测试性接口获取还需要研发根据实际情况做出调整。无论如何,由于业务本身的复杂性,我们不可能寄希望于使用一个工具生成所有代码,一定有一部分代码是工具所无法完成的,依然需要人来参与。但是这部分工作可以通过 Copilot 、IDE 插件等工具来辅助提效。
05
总结
各位仍需注意,如果直接使用 ChatGPT 有敏感信息泄露风险,各团队可以根据需要独立部署AI模型。对于个人开发者可以使用一些开源模型,例如 Vicuna、LLaMA 等。迄今为止 AI 工具的出现主要还是为了便利人类,而不是代替人类。加以学习利用,这些工具也许能为帮助开发提速。欢迎开发者们在评论区交流。原创作者|邬俊杰技术责编|张晋铭


