




大家好,我是互联网架构师。
我们在低代码领域探索了很多年,从2015 开始研发低代码前端渲染(amis),从 2018 年开研发后端低代码数据模型,发布了爱速搭低代码平台,这些年调研过了几乎所有市面上的相关技术和产品,发现虽然每家产品细节都不太一样,但在底层技术上却只有少数几种方案,因此我们认为不同产品间的最大区别是实现原理,了解这些实现原理就能知道各个低代码平台的优缺点,所以本文将会介绍目前已知的各种低代码实现方案,从实现原理角度看低代码。
01
本文里的「低代码」指的是什么?
在讨论各个低代码方案前,首先要明确「低代码」究竟是什么?
这个问题不好直接回答,因为低代码是非常宽泛的概念,有很多产品都声称自己的低代码,但我们很容易反过来回答另一个问题:「什么是低代码产品唯一不可缺少的功能?」
我认为这个功能是可视化编辑,因为非可视化编辑就是代码编辑,而只有代码编辑的产品不会被认为是低代码,因此可视化编辑是低代码的必要条件,低代码其实还有另一个更清晰的叫法是可视化编程。
既然可视化编辑是低代码的必要条件,那从实现角度看,实现可视化编辑有什么必要条件?
我认为可视化编辑的必要条件是「声明式」代码,因为可视化编辑器只支持「声明式」代码。
解释一下什么是「声明式」,除了声明式之外还有另一种代码模式是「命令式」,我们分别举两个例子,如果想绘制一个红色区块,用「声明式」来实现,可以使用 HTML+CSS,类似下面的方法:
<div style=”background:red; height:50px”></div>
而换成用「命令式」来实现,可以使用 Canvas API,类似下面的方法:
-
const ctx = canvas.getContext(‘2d’); -
ctx.fillStyle = ‘red’; -
const rectangle = new Path2D(); -
rectangle.rect(0, 0, 100, 100); -
ctx.fill(rectangle);
-
「声明式」直接描述最终效果,不关心如何实现。 -
「命令式」关注如何实现,明确怎么一步步达到这个效果。
-
「声明式」可以直接从展现结果反向推导回源码 -
「命令式」无法做到反向推导
-
const ctx = canvas.getContext(‘2d’); -
ctx.beginPath(); -
ctx.moveTo(0, 0); -
ctx.lineTo(50, 0); -
ctx.strokeStyle = ‘#ff0000’; -
ctx.lineWidth = 100; -
ctx.stroke();
-
HTML+CSS 是一种页面展现的 DSL -
SQL 是一种数据查询及处理的 DSL -
K8S 的 yaml 是一种服务部署的 DSL -
NGINX conf 是一种反向代理的 DSL
-
容易上手,因为描述的是结果,语法可以做得简单,非研发也能快速上手 HTML 及 SQL。 -
支持可视化编辑,微软的 HTML 可视化编辑 FrontPage 在 1995 年就有了,现在各种 BI 软件可以认为是 SQL 的可视化编辑。 -
容易优化性能,无论是浏览器还是数据库都在不断优化,比如可以自动改成并行执行,这是命令式语言无法自动实现的。 -
容易移植,容易向下兼容,现在的浏览器能轻松渲染 30 年前的 HTML,而现在的编译器没法编译 30 年前的浏览器引擎代码。
-
功能取决于运行环境,比如浏览器对 CSS 的支持程度决定某个属性是否有人用,虽然出现了CSS Houdini 提案,但 Firefox 和 Safari 都不支持,而且上手成本太高,预计以后也不会流行。 -
性能取决于运行环境,比如同一个 SQL 在不同数据库下性能有很大区别。 -
对使用者是黑盒,使用者难以知道最终实现,就像很少人知道数据库及浏览器的实现细节,完全当成黑盒来使用,一旦遇到性能问题就不知所措。 -
技术锁定,因为即便是最开放的 HTML 也无法解决,很多年前许多网站只支持 IE,现在又变成了只支持 Chrome,微软和 Opera 在挣扎了很多年后也干脆直接转向用 Chromium。同样的即便有 SQL 标准,现在用的 Oracle/SQL Server 应用也没法轻松迁移到 Postgres/MySQL 上。低代码行业未来也一样,即便出了标准也解决不了锁定问题,更有可能是像小程序标准那样发展缓慢,功能远落后于微信。
-
低代码的各种优点是「声明式」所带来的。 -
低代码被质疑的各种缺点也是「声明式」所导致的。
02
低代码的实现方案
-
强依赖研发,无法做到给非研发使用,因为后续代码需要编译上线。 -
无法持续可视化编辑,因为代码无法可视化编辑,生成代码后只要有修改就没法再反向还原成低代码的形式,后续只能代码编辑。 -
难以实现完全用低代码开发应用,因为不能生成太复杂的代码,使得这种方案一般不包括交互行为,通常是只有前端界面支持可视化编辑。 -
无法做到向下兼容,因为生成的那一瞬间代码依赖的框架版本就固定了,目前还没见过哪款前后前端框架做过到完全向下兼容。
03
前端代码实现原理 – 界面渲染
-
{ -
“type”: “page”, -
“title”: “页面标题”, -
“subTitle”: “副标题”, -
“body”: { -
“type”: “form”, -
“title”: “用户登录”, -
“body”: [ -
{ -
“type”: “input-text”, -
“name”: “username”, -
“label”: “用户名” -
} -
] -
} -
}
-
<Page title=”页面标题” subTitle=”副标题”> -
<Form title=”用户登录”> -
<InputText name=”username” label=”用户名” /> -
</Form> -
</Page>
-
低代码平台编辑器几乎都是基于 Web 实现,JavaScript 可以方便操作 JSON。 -
JSON 可以支持双向编辑,它的读取和写入是一一对应的。
-
paths: -
root_path: &root -
val: /path/to/root/ -
patha: &a -
root_path: *root
-
{ -
“paths”: { -
“root_path”: { -
“val”: “/path/to/root/” -
}, -
“patha”: { -
“root_path”: { -
“val”: “/path/to/root/” -
} -
} -
} -
}
-
不支持注释 -
不支持多行字符串 -
语法过于严格,比如不支持单引号,不能在最后多写一个逗号

-
Vue 还是 1,现在已经到 3 了,不向下兼容。 -
Angular 还是 1,现在已经 13 了,不向下兼容。 -
React 虽然整体用法没变,但有大量细节不向下兼容,加上 hooks 推出后,许多第三方库改成了 hooks 版本,导致旧的类组件形式没法直接使用。
04
交互逻辑的实现
-
使用图形化编程 -
固化交互行为 -
使用 JavaScript
-
function JSONTraverse(json, mapper) { -
Object.keys(json).forEach(key => { -
const value = json[key]; -
if (isPlainObject(value) || Array.isArray(value)) { -
JSONTraverse(value, mapper); -
} else { -
mapper(value, key, json); -
} -
}); -
}
 Blender 中的材质节点编辑
Blender 中的材质节点编辑
 来自 UE4 Blueprints From Hell 里的一张图
来自 UE4 Blueprints From Hell 里的一张图-
{ -
“label”: “弹框”, -
“type”: “button”, -
“actionType”: “dialog”, -
“dialog”: { -
“title”: “弹框”, -
“body”: “这是个简单的弹框。” -
} -
}
-
可以可视化编辑 -
整合度高,比如弹框里可以继续使用 amis 配置,通过嵌套实现复杂的交互逻辑
 RDA Studio 11 的界面编辑
RDA Studio 11 的界面编辑05
后端低代码的方案
-
所有方案里唯一支持直连外部数据库,可以对接已有系统。 -
性能高和灵活性强,因为可以使用高级 SQL。 -
开发人员容易理解,因为和专业开发是一样的。
-
需要账号有创建用户及 DDL权限,如果有安全漏洞会造成严重后果,有些公司内部线上帐号没有这个权限,导致无法实现自动化变更。 -
DDL 有很多问题无解,比如在有数据的情况下,就不能再添加一个没有默认值的非 NULL 字段。 -
DDL 执行时会影响线上性能,比如 MySQL 5.6 之前的版本在一个大数据量的表中添加索引字段会锁整个表的写入(但也有数据库不受影响,比如 TiDB、OceanBase 支持在线表结构变更,不会阻塞读写)。 -
部分数据库不支持 DDL 事务,比如 MySQL 8 之前的版本,导致一旦在执行过程中出错将无法恢复。 -
实现成本较高,需要实现「动态实体」功能,如果要支持不同数据库还得支持各种方言。
 爱速搭里的数据库模型
爱速搭里的数据库模型-
用户创建一个自定义表的时候,系统就自动创建一个 collection,所有这个表的数据都存在这个 collection 里。 -
用户新增字段的时候,就随机分配一个 fileId,后续对这个字段的操作都自动映射到这个 fileId 上,用 fileId 的好处是用户重命名字段后还能查找之前的数据,因为所有数据查询底层都基于这个 fileId。 -
查询的时候先找到对应的 collection,再通过 meta 信息查询字段对应的 fileId,使用这个 fileId 来获取数据。
-
无法支持外部数据库,数据是孤岛,外部数据接入只能通过导入的方式。 -
MongoDB 在国内发展缓慢,接受度依然很低,目前还没听说有哪家大公司里最重要的数据存在 MongoDB 里,一方面有历史原因,另一方面不少数据库都开始支持 JSON 字段,已经能取代大部分必须用 MongoDB 的场景了。 -
不支持高级 SQL 查询。
-
CREATE TABLE wp_postmeta ( -
meta_id bigint(20) unsigned NOT NULL auto_increment, -
post_id bigint(20) unsigned NOT NULL default ‘0’, -
meta_key varchar(255) default NULL, -
meta_value longtext, -
PRIMARY KEY (meta_id), -
KEY post_id (post_id), -
KEY meta_key (meta_key) -
) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
-
查询性能低,如果有 10 个字段就要查 10 行。 -
无法支持 SQL 高级查询,因为数据是按行存的。

-
tenant_id 是租户 id,用于隔离不同租户 -
table_id 是自定义表的 id -
uuid 是具体这一行数据的 id -
后面的 value0 到 value500 都是预留的列,用于存储实际数据,一般使用变长字符串类型

-
tenant_id 和 table_id 和前面一样。 -
field_id 对应的是给这个「标题」字段分配的 id。 -
value_index 对应前面那个 data 表里预览列的位置,比如这个值是 0,就意味着 value0 列被分配给了这个「标题」字段。 -
name 用来存名称,type 用来标识类型,这样查询和写入数据的时候,首先从这里查询 value_index 是什么,然后再去前面那个预留列的表中查询对应列的值。
-
因为存储只能是字符串,所以对于日期、数字等其他类型,因此读取的时候需要根据类型使用数据库里的函数进行转换,比如 STR_TO_DATE。 -
需要单独处理唯一性功能,因为这个数据表是所有租户共用的,没法设置表级别的唯一性索引,这时就需要新建一个表来单独做,坏处是数据多份容易产生不一致,需要在所有更新操作都加事务。 -
需要单独处理索引功能,同样是因为字段是字符串,因此没法直接在 data 表里加索引,如果数据存储的是数字,排序就是错的,为了解决这个问题需要另外创建一个一个包含常见字段的索引表,数据更新的时候。 -
自增字段需要自己实现。 -
元数据信息需要缓存,不然每次查询前都需要先查询元数据信息,然后再去查询真正的数据。
-
比起第一种原生数据库表方案,它不需要 DDL 操作,不容易出问题,跟适合 SaaS 产品。 -
比起第二种文档型数据库方案,它的存储使用更为成熟的关系型数据库,相关的运维工具多。 -
比起第三种行代替列方案,它的查询性能好,因为是读取一行数据。
-
无法支持 SQL 所有功能,比如 force.com 的 SOQL 无法 select *、没有视图、不支持写入和更新数据,通过这个特点就能识别出使用这个方案的产品,这类产品虽然看起来很像在用传统数据库,也支持使用 SQL,但这个 SQL 一定是受限的。 -
数据泄露风险高,因为所有租户的数据都存在一张表里,而数据库都不支持行级别权限的账号,所以意味着所有租户其实共享一个数据库账号,只要有某个功能的查询漏了加租户过滤就能查到所有租户数据。相比之下前面提到的原生表及文档型数据库方案都能直接使用数据库自带的账号进行有效隔离。 -
一些数据库高级字段难以支持,比如坐标数据、二进制类型等,只能用单独的表存,导致了查询开销。 -
整体实现成本高,其中很多细节需要处理好,比如保证数据一致性,因为为了实现唯一性、索引等功能需要拷贝数据,更新的时候要同时更新。
-
技术薄弱的开发者不会用,比如因为 App Engine 是分布式部署,导致上传文件不能放本地,必须改成对象存储,所以没法直接用 WordPress 没法用,对于小站长来说还不如用虚拟主机。 -
对于有技术实力的开发者,又会觉得平台能力受限,不利于自己后续发展,比如谷歌的 App Engine 直到 2019 年才支持 WebSocket。
-
实现简单,部署成本低,因为表的存储就是单文件。 -
容错性强,数据类型都是靠前端处理的,不会出现存数据库导致。
-
如果要支持行列级别权限校验,还得在后端实现一遍过滤,而每次都加载一个巨大的 JSON 文件对服务器内存有较高要求。 -
难以支持事务操作,尤其是支持行级别的操作。 -
目前看十万级别数据处理可以只靠前端,但再大量的数据就不合适了,一次性加载太多对带宽和浏览器内存要求比较高。 -
只能当成 Excel 的替代品,数据是孤岛,不能直连外部数据库。
-
逻辑图形化,这个目前看各个产品效果都不太理想,看上去还不如代码易读。 -
固定行为,主要是对数据存储提供增删改查操作。 -
支持 JavaScript 自定义。 -
简化 DSL 语言,类似 Excel 中的公式。
-
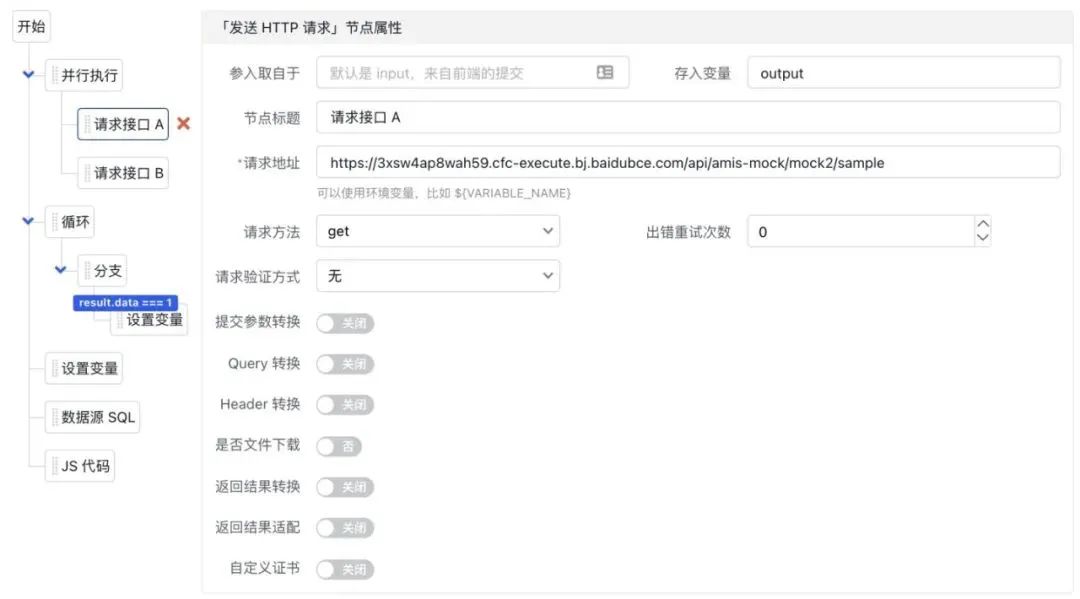
默认从上往下执行,但有个特殊的「并行执行」节点可以并行执行。 -
对于循环和分支会创建子节点,并且子节点可以无限嵌套,相当于代码里的花括号。 -
节点可以折叠,这样就能先将复杂的逻辑折叠起来方便看主流程,这是使用图模式难以实现的,在图里收起后无法修改其它节点的位置,导致空出一块。

-
{ -
“lines”: [ -
{ -
“id”: “d4ffdd0f6829”, -
“to”: “4a055392d2e1”, -
“from”: “e19408ecf7e3” -
}, -
{ -
“id”: “79ccff84860d”, -
“to”: “724cd2475bfe”, -
“from”: “4a055392d2e1” -
} -
], -
“nodes”: [ -
{ -
“id”: “e19408ecf7e3”, -
“type”: “start”, -
“label”: “开始” -
}, -
{ -
“id”: “4a055392d2e1”, -
“type”: “examine-and-approve-task”, -
“label”: “审批节点” -
}, -
{ -
“id”: “724cd2475bfe”, -
“type”: “end”, -
“label”: “结束” -
} -
] -
}
06
低代码平台未来会怎样?
-
易用性强 -
灵活性差 -
适合小公司,客单价低,但客户数多 -
标准化程度高,导致功能都很类似,将面临同质化竞争 -
产品使用简单,客户支持成本低
-
易用性弱 -
灵活性强 -
适合中大型公司,客户数少,但客单价高 -
标准化程度低,每家都有各自的特点 -
产品使用复杂,客户支持成本高
07
总结
-
低代码都是一种「声明式」编程,因为只有声明式才能可视化编辑,而可视化编辑是低代码唯一不可少的功能。 -
低代码的优缺点其实来自于「声明式」本身。 -
编写代码是一种抽象思维,因此并不适合可视化,导致低代码只能面向特定领域,复杂应用需要和专业开发配合。 -
前端界面的 HTML+CSS 可以认为是一种低代码 DSL,因此界面的低代码比较容易实现,只需要在 HTML+CSS 基础上抽象一层。 -
后端存储的低代码有几种方案,但没有哪个方案是完美的,它们都有各自的优缺点,这将决定一个低代码平台的适用范围,建议在选型时重点关注。
08
在了解原理之后
 amis 的 contributors 页面
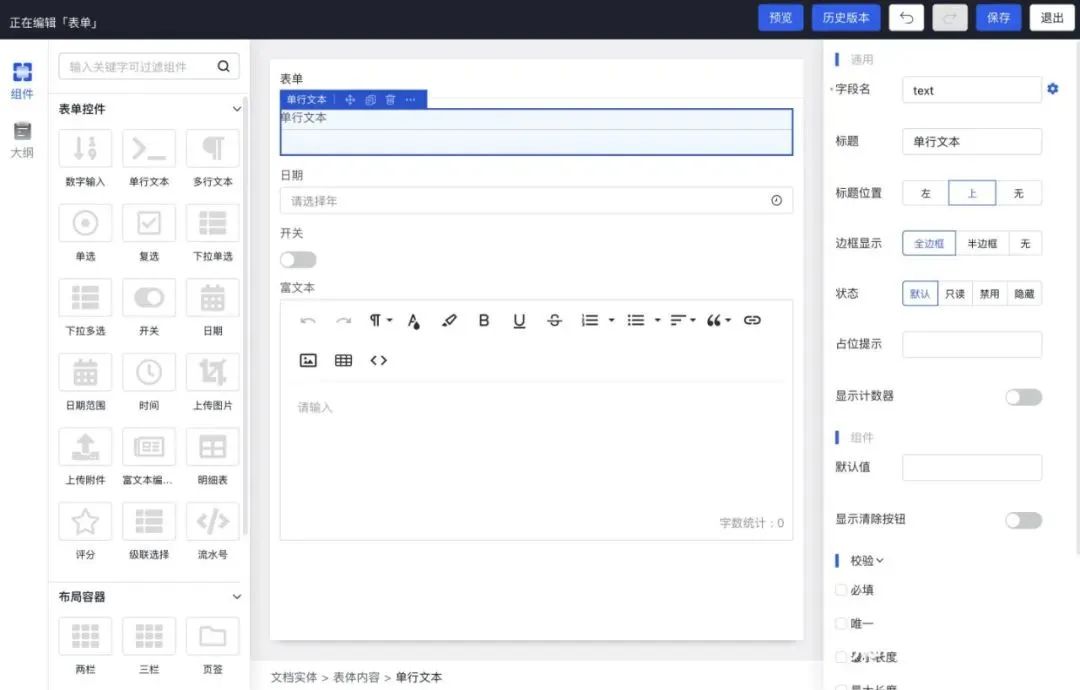
amis 的 contributors 页面 amis 1.6.0 里的日期选择
amis 1.6.0 里的日期选择– END –




