-
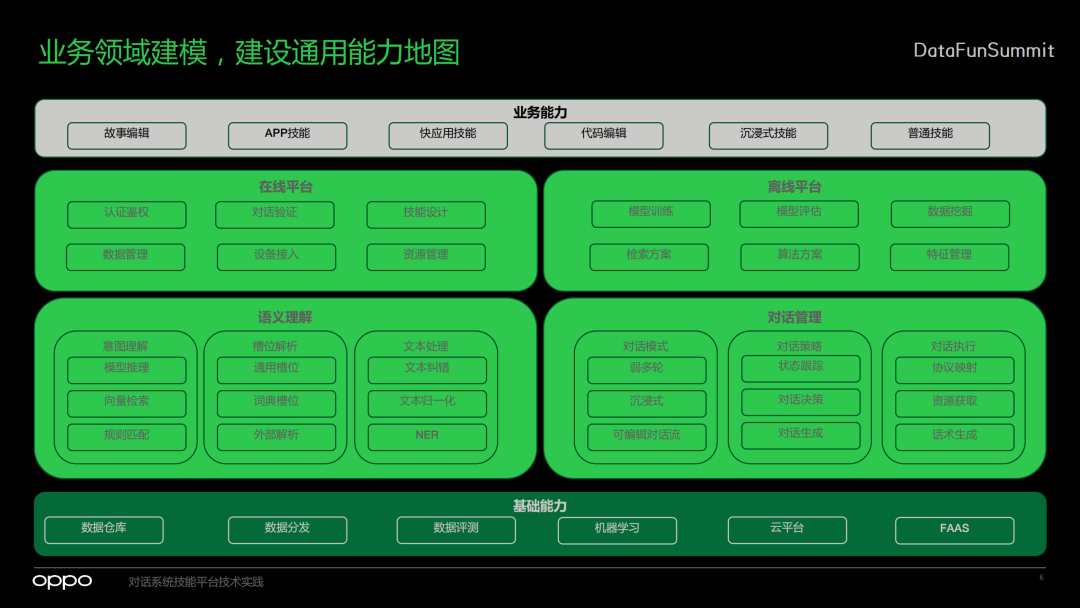
业务领域建模,建设通用能力地图
-
语义理解能力初探,多类型的场景支持
-
多模式易扩展流程化的对话管理
-
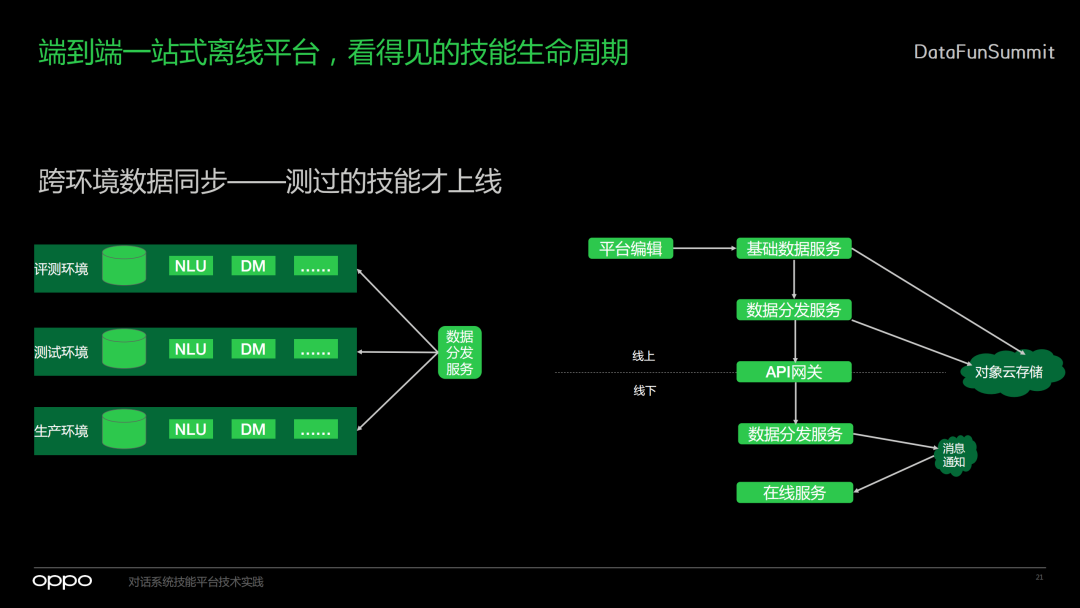
端到端一站式离线平台,看得见的技能生命周期
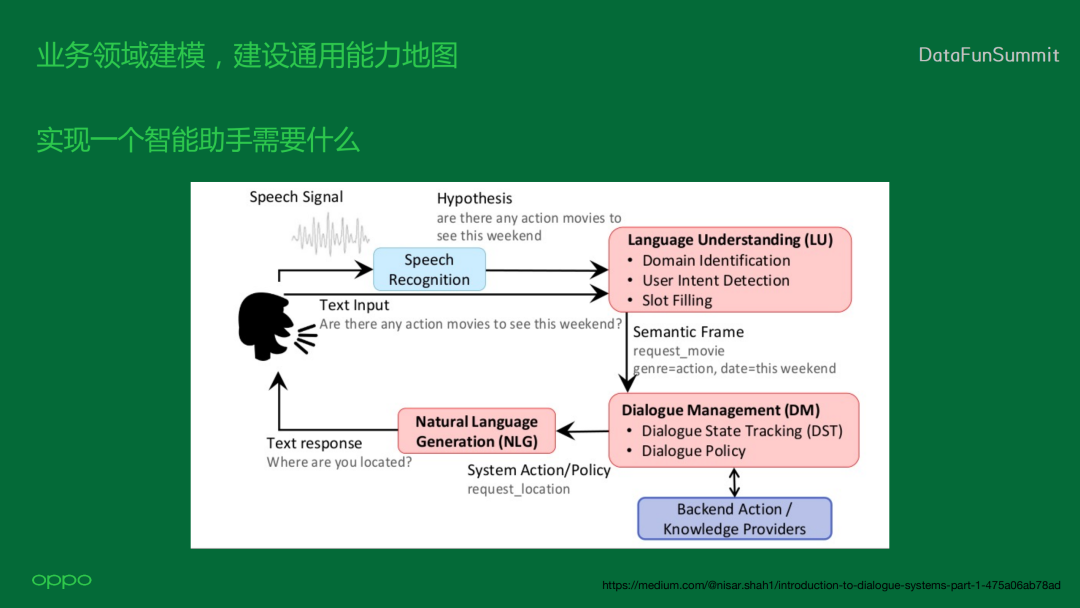
1. 实现一个智能助手需要什么

2. 什么是技能平台
1. 通用化NLU流程

-
基于模型,我们可以将用户的语料自动训练成一个模型,再上传到技能;
-
基于匹配,当用户的语料非常少的时候,我们会推荐他用这种匹配方案去实现一些高精准的匹配;
-
基于知识,对于一些问答类的语料,我们会推荐他用第三种,也就是基于知识的NLU识别。
-
首先是预处理,主要包含文本纠错、文本归一化和query改写。归一化是比如特殊字符的处理、大小写转换等,有时候语音转换的query不符合用户上下文,我们还需要改写query。
-
之后是前处理,对于模型,我们需要做数值化,通过数值化进行预测,所以我们会做字向量或词向量的数值化。同时,我们也会嵌入定义好的一些知识,将知识嵌入到模型当中,做一次数值的处理。
-
前处理完成后,我们会将数值向量传到模型中去做预测。如果不用模型,我们会支持用户编辑一些规则,通过规则引擎实现精准匹配。对于这种匹配,我们还支持向量检索的方式,能够从语义的层面去做一些检索。
-
当我们识别到用户的意图之后,就需要去做槽位的处理。我们定义了几种槽位,一种是基于词典的槽位提取,我们有自研的DAG + DP的词典提取的方法。同时,我们还定义了几十种通用的槽位,方便外部用户进行常规的槽位提取,不需要提供他自己的词典,比如说提取城市、数字、人名等通用的槽位,只要选择就可以了。我们还会接入一些三方,如果他自己有NLU能力,我们也可以让他接入他自己的三方槽位。部分技能有模型训练的能力,我们也支持他去接入一些模型槽位。
2. 基于模型的意图识别
-
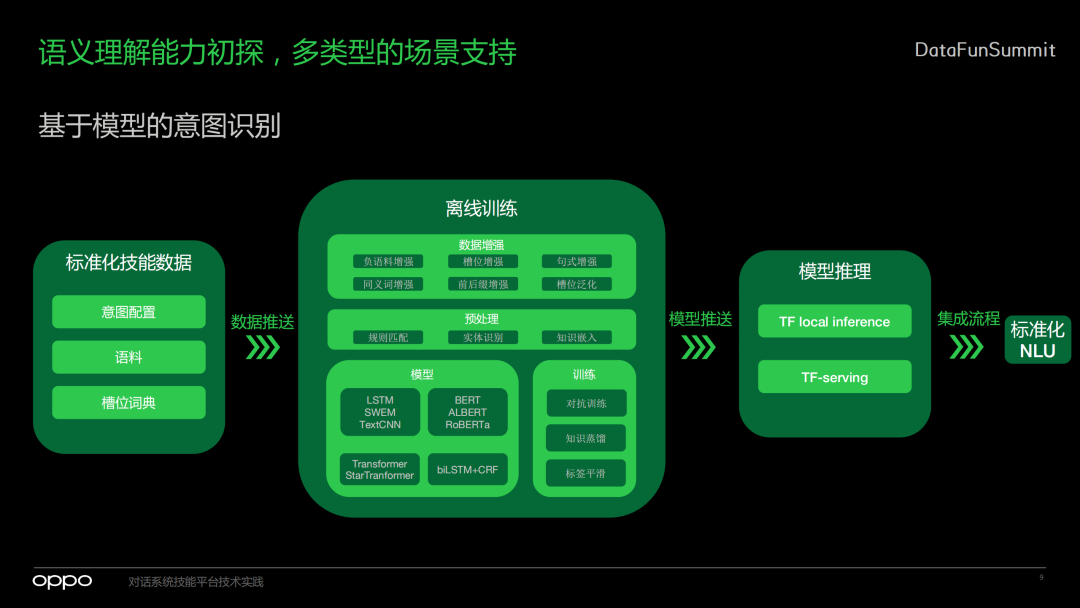
首先是定一些标准化的技能数据,包括意图配置,比如定义技能可能有三个意图,每个意图会有一些什么样的槽位,对于每个意图它需要去提供标准化的语料,可以提供一些正语料,也可以提供一些负语料,还可以去配置它的槽位词典,这里主要是用户自定义的词典。
-
这些信息会放到离线训练的系统当中,离线训练系统会做数据增强。对于配置的负语料会做负语料的增强,提取的槽位也会做槽位的增强。如果配置了规则也会进行句式的增强,还会做一些泛化。数据增强之后进行预处理,主要是实体识别、知识嵌入。在基本的数据处理完之后,就会把它放到模型里。这里定义了几类通用的模型去做整个意图识别的训练。
-
训练完之后再通过知识蒸馏等等生成一个真正可以进行推理的模型。对于一些小的模型,我们会直接做local的inference,效率更好。而对于一些大的模型,我们会用TF serving的方式进行预测。
-
生成模型之后,我们会集成流程去做标准化NLU,也就是我们前面提到的预处理、前处理、意图识别和槽位提取。
3. 基于检索的意图识别

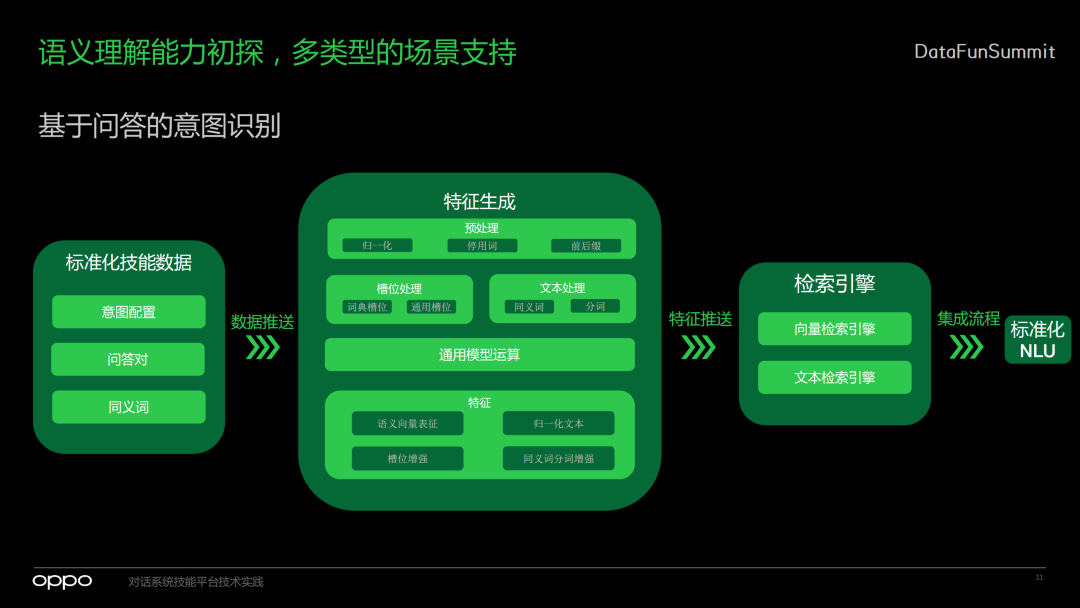
4. 基于问答的意图识别
5. 组件化核心功能,算子化编排服务

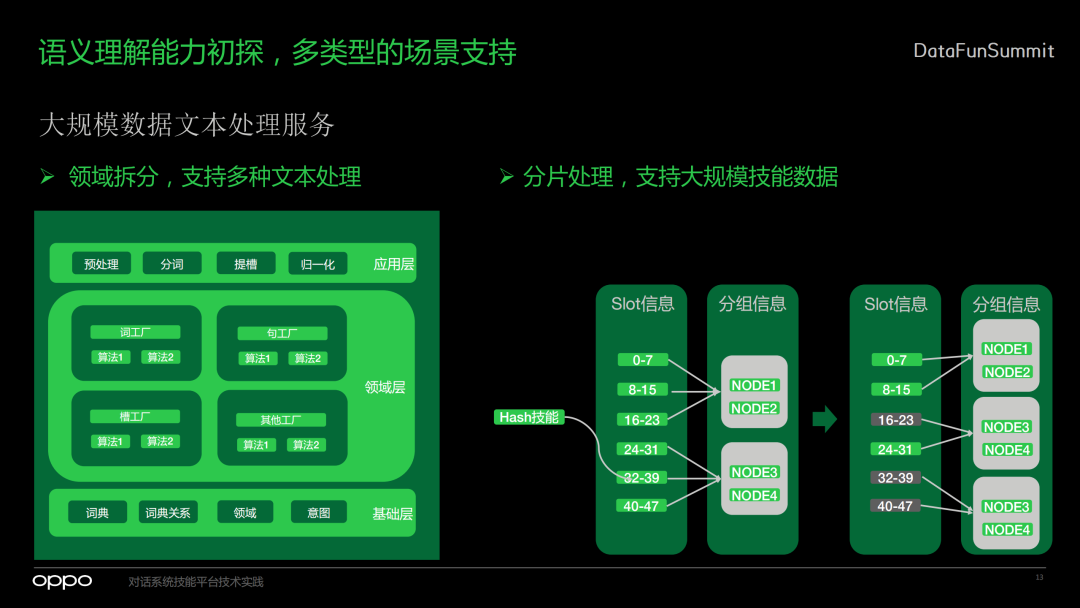
6. 大规模数据文本处理服务
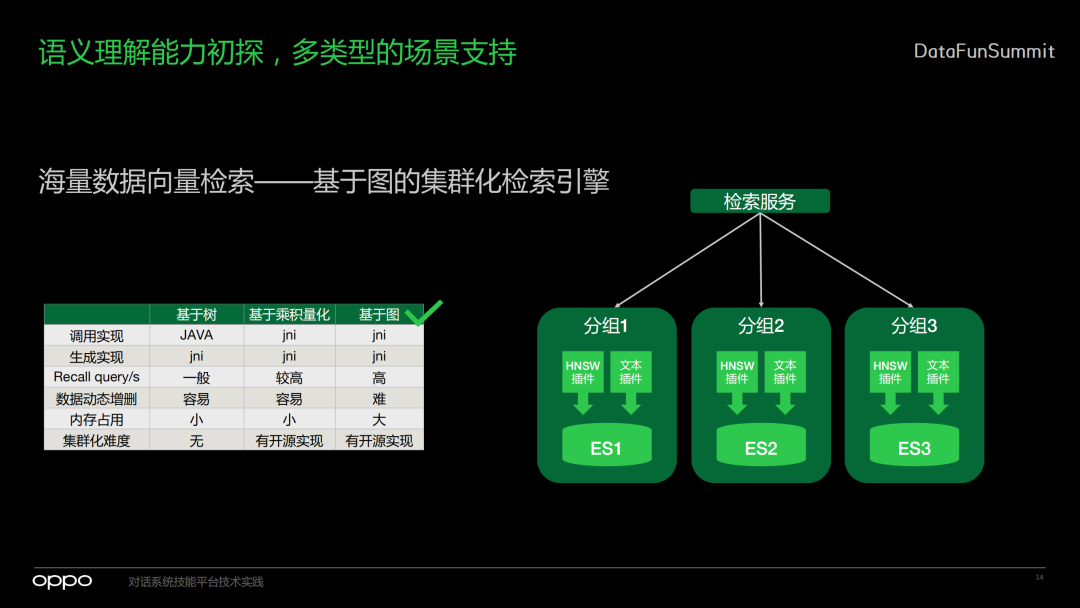
7. 向量检索
前面讲了我们在语义模块做的一些工作,接下来讲我们怎样做对话管理,也就是怎么去执行动作。
1. 对话管理总览
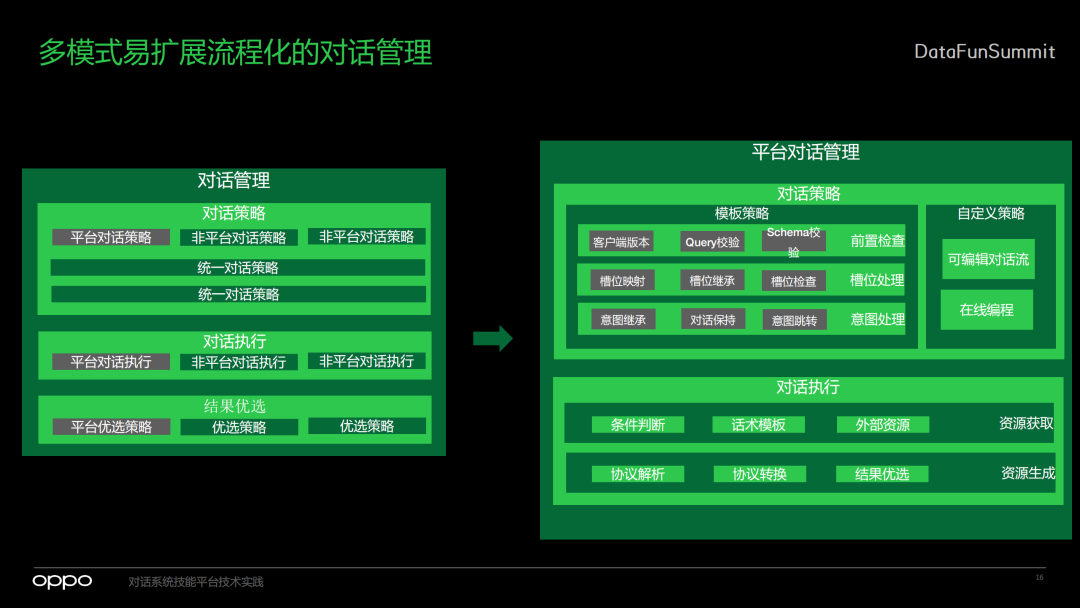
-
首先是对话策略部分。小布助手里面有很多技能,既包含平台的技能,也有非平台的技能。我们首先要将对话策略和其他非平台的技能进行汇总,然后在统一对话策略的不同层级里面影响整个对话的结果。
-
下一步是对话的执行,同样也有平台对话执行和非平台对话执行,在中控系统中会对这些执行去做一次整体的收集。
-
收集之后进行结果的优选,有不同的优选策略,也会用到我们平台自定义的优选策略,最终为用户带来结果展示。
2. 统一对话协议,自定义对话状态控制

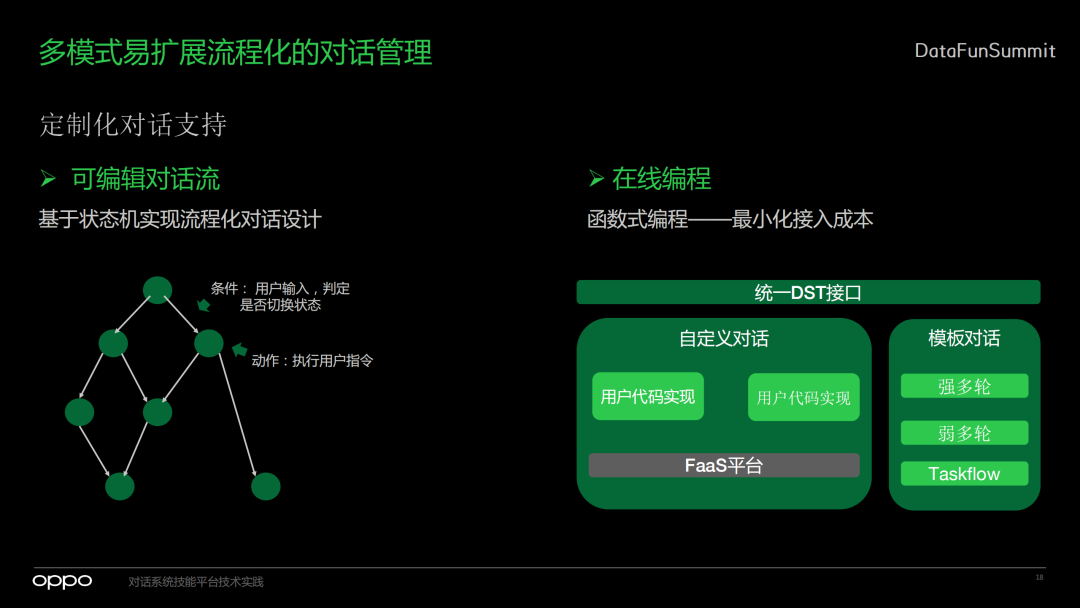
3. 定制化对话支持
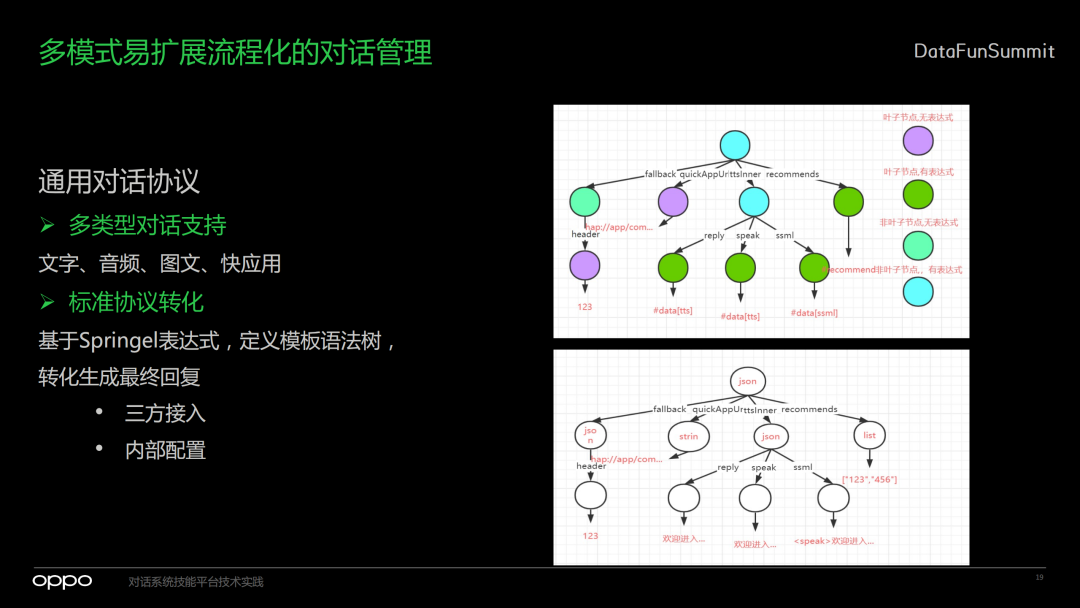
4. 通用对话协议
1. 跨环境数据同步
2. 线上数据挖掘


– END –