








前不久,获得亚马逊40亿美元投资的ChatGPT主要竞争对手Anthropic在官网公布了一篇名为《朝向单义性:通过词典学习分解语言模型》的论文,公布了解释经网络行为的方法。
由于神经网络是基于海量数据训练而成,其开发的AI模型可以生成文本、图片、视频等一系列内容。虽然一些数学题、推理我们可以看到正确结果,例如,AI模型会告诉你1+1=2这个结果,却无法解释这个过程是如何产生的。即便进行简单解释,也只是基于语义上的理解。
就像人类做梦一样,可以说出做梦的内容,却无法解释梦境到底是怎么形成的。
Anthropic根据Transformer模型进行了一个小型实验,将512个神经单元分解成4000多个特征,分别代表 DNA 序列、法律语言、HTTP 请求、营养说明等。研究发现,单个特征的行为比神经元行为更容易解释、可控,同时每个特征在不同的AI模型中基本上都是通用的。
ChatGPT等大语言模型经常出现幻觉、歧视、虚假等信息的情况,主要是人类无法控制其神经网络行为。所以,该研究对于增强大语言模型的准确率、安全性,降低非法内容输出帮助非常大。
论文地址:https://transformer-circuits.pub/2023/monosemantic-features/index.html#phenomenology-feature-splitting

为了更好地理解Anthropic的研究,「AIGC开放社区」先为大家简单解读几个技术概念。
什么是神经网络
神经网络是一种模仿人脑神经元结构的计算模型,用于解决各种复杂的计算问题,主要用于模式识别、数据挖掘、图像识别、自然语言处理等领域。
神经网络的核心组成部分是神经元,它们通过一系列的权重连接在一起,形成一个大型网络结构。
主要包括3个层:1)输入层,用于接收原始数据,并将其传递给网络的下一层;2)隐藏层,是网络中的核心部分,包含了一系列神经元用于处理输入数据并产生输出;3)输出层,将隐藏层的结果汇总并产生最终的输出。
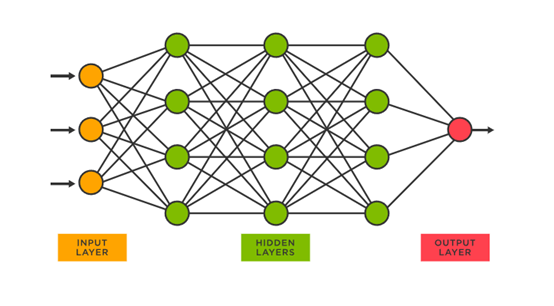
简单来说,神经网络就是模仿人类的大脑思维与思考、解读问题。神经元就相当于人脑中的放电神经元。
经过几十年的研究,科学家们可以大概了解人脑神经元的运行规律,但仍然有很多谜团无法解开,例如,大脑是如何产生情感、梦境、独立思想等。所以,想深度解释神经网络的工作原理同样不容易。
什么是神经元
神经元是神经网络的基本组成部分,主要对数据进行输入、计算和输出。
神经单元的工作原理模拟了人脑中神经元的工作方式,接收一个或多个输入,每个输入都有一个对应的权重。这些输入和权重的乘积被加总,然后加上一个偏置项。得到的总和被送入一个激活函数,激活函数的输出就是这个神经单元的输出。
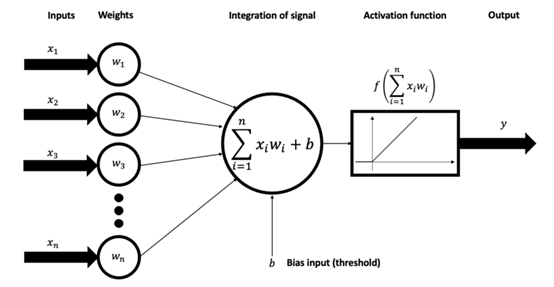
在神经网络的训练过程中,网络会不断调整这些权重和偏置项,以便更好地预测或分类输入数据。
这个调整过程通常通过一种叫做“反向传播的算法”来完成,配合梯度下降或其他优化方法来最小化预测错误。 神经单元有很多种,包括线性单元、sigmoid单元、ReLU单元等,区别在于使用的激活函数不同。
Anthropic研究简单介绍
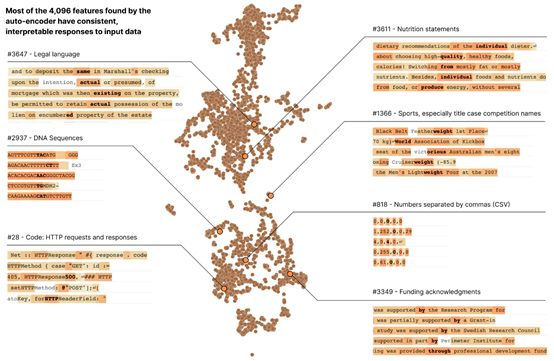
为了解释神经网路行为,Anthropic基于Transformer模型将512个神经元分解成4000多个特征。这些特征分别代表DNA 序列、法律语言、HTTP 请求、希伯来语文本、营养声明等,然后进行一系列行为操作观察。
研究结果表明,单个特征的行为比神经元行为更容易解释、可控,同时每个特征在不同的AI模型中基本上都是通用的。
为了验证其研究,Anthropic创建了一个盲评系统,来比较单个特征和神经元的可解释性。特征(红色)的可解释性得分远高于神经元(蓝绿色)。
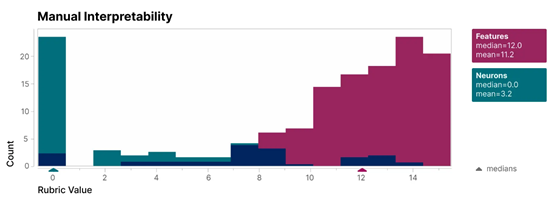
Anthropic还采用“自动解释性”方法,使用大型语言模型生成小模型特征的简短描述,根据另一个模型的描述预测特征激活的能力对其进行评分。
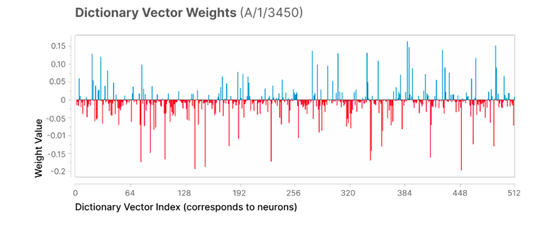
同样,特征的得分高于神经元,这表明特征的激活及其对模型行为的下游影响具有一致的解释。
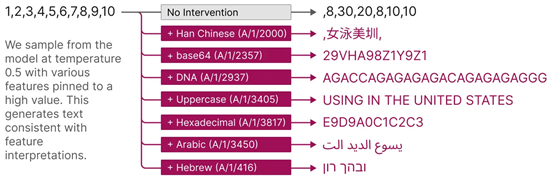
此外,还提供了有针对性的模型引导方式。人为激活某个功能,会导致模型行为以可预测的方式发生变化。
神经网络对大语言模型的重要性
神经网络是大语言模型的重要基石,例如,OpenAI的GPT系列模型是基于Transformer的神经网络架构开发而成。
大语言模型使用神经网络来处理和生成文本。在训练过程中,这些模型会学习如何预测文本序列中的下一个词,或者给定一部分文本后续的可能内容。
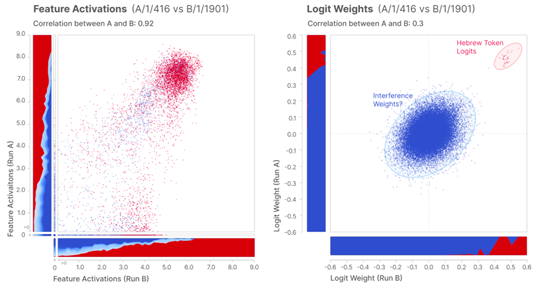
为了做到这一点,模型需要理解语言的语法、语义、以及在一定程度上的上下文。简单来说,神经网络提供了处理和生成自然语言的计算框架,而大语言模型则通过这个框架来理解和生成文本。
所以,理解神经网络行为,对增强大语言模型的安全性、准确性至关重要。
– END –
报告下载

大佬观点


