




作为一个从事14年低代码研发者甚至倡导者,在ChatGPT席卷全球的形式下,度过了纠结困惑的一年。
低代码的主张:“降低代码开发量,通过点击配置、图形化拖拽开发应用,人人都是公民开发者”;大模型的主张:“不用代码开发,通过自然语言生成应用,人人都是开发者”。显然后者是降维打击,低代码的方向在哪里?一时间,最好的朋友都劝我,放弃低代码吧,大模型是低代码的终结者。
于是半年多,在大环境的压力下,研究很多大模型技术,从各个角度突破找不到,更加纠结。
然而一年多的时间,事实表明绝大部分应用没有通过大模型的自然语言生成,充分证明大模型并没有替代开发者。
而正在困惑中,这几个月,多款辅助开发的Copilot的产品却大获成功。
终于决定了大模型应用于低代码的技术路线,经过团队的开发实践,最终落地形成产品CodeGPT。
春节之际,静下心来,撰写此文,分享同行,相互交流。
本文首先重温一下低代码概念并说明笔者认知中低代码模型,然后介绍大模型在开发上的作用,接着提出低代码面对大模型的挑战,并提出低代码大模型的架构,最后介绍CodeGPT产品的落地。
01
低代码的模型
我们需要重新认识一下低代码,看看低代码的概念,对概念做深入分析,我们总结一下低代码的模型。
1、低代码的概念
对于我们这个领域来说,低代码概念其实已经非常清楚了,但是,我们还是重新回顾一下,看一下智谱清言给出的定义:
低代码(Low-Code)是一种使用图形界面进行应用程序设计和开发的平台或工具,从而降低了编程的难度,使非专业开发人员也能进行应用开发。低代码平台通常提供拖放式的组件、预制的模型和模板,以及可视化的开发环境,允许开发者通过最小的手工编程来创建应用程序。
使用低代码平台可以大大缩短应用程序的开发周期,提高开发效率,降低成本。这些平台通常支持各种业务流程和数据库集成,并能运行在不同的设备上,如桌面电脑、移动电话和平板电脑等。
低代码开发平台适合快速原型开发、业务流程自动化、以及应用程序的定制开发。它对于希望快速响应市场变化、缺乏充足IT资源的组织特别有用。
在中国,低代码开发也正逐渐被广大企业和开发者接受和应用,与国内的创新发展和产业升级相结合,为各行各业提供数字化转型的新路径。它与中国的社会主义现代化建设同步推进,助力提升生产力,推动经济高质量发展。
2、概念的深入分析
1、低代码的作用:降低开发难度、开发成本,缩短开发周期;
2、应用的广泛性:目前各行各业已经普遍应用,这是领域的共识了;
3、图形化开发方式:图形化拖拽和点击式配置方式开发;
4、少量手工编码:手工编码没有被完全替代,很多开发平台已经将其转换为脚本开发方式;
5、大量的预制:预制的组件、预制的模型和预制的模板,这里我们统称为预制件;
6、应用的范围:页面、流程、数据等等。
前两项已经是业内的共识了,我重点针对后面4项稍作展开分析。
2.1.图形化开发
-
图形化拖拽(拖放)
-
点击式配置
-
图形化配置
-
零代码开发
-
..
用户输入方式有两种:
-
鼠标点击拖拽输入
-
键盘短文本(标签为主)输入
-
预制模版:图形化界面形成参数,替换模板的变量做代码生成; -
预制模型:图形化界面形成配置文件,供模型做解释执行;
之所以称之为低代码而不是“无代码”,手工编码是无法被图形化开发完全替代的(或者说如果图形化开发完全替代手工编码,图形化开发的复杂度会远远超过编码),少量的手工编码是必须保留的。
而目前,各个低代码开发平台基本上将手工编码的工作转换为脚本编写,同时预制了大量的函数库或接口,来降低学习难度和开发成本。
低代码领域常见的脚本有:
(1)sql,用于数据库查询;
(2)javascript,常用于前端逻辑;
(3)groovy,常用于后端逻辑;
(4)表达式,常用于逻辑分支;
(5)正则表达式,常用于数值验证;
(6)低代码DSL:各个厂家根据领域专业定制语言。
这里重点说明一下DSL,指的是“领域特定语言”(Domain-Specific Language)。这是一种用于特定问题领域的编程语言或脚本语言,它为某个特定应用领域或问题域提供了一套专门的语法和语义。DSL的设计目的是简化特定领域内软件的开发和维护,使得领域专家能够更加直接地参与软件开发过程,而不需要深入了解通用的编程语言和软件开发技术。DSL的优势包括:
-
专注于特定领域:DSL的设计紧密围绕特定领域的概念和需求,使得在该领域内的问题解决更加高效和自然;
-
简洁明了的语法:DSL通常具有简洁和直观的语法,使得领域专家能够容易地理解和使用。
-
出错概率更低:与通用语言项目,简洁直观的语法,会大大减少出错概率;
-
可扩展性:DSL可以被扩展,以适应新的需求和变化,而无需完全重新设计。
-
易于集成:DSL可以与通用编程语言和工具集成,允许领域专家在不需要深入了解通用编程的情况下构建复杂的软件系统。
2.3.大量的预制
“预制”行业内不同厂家的说法有:
-
封装
-
继承
-
沉淀
-
积累
1、预制前端组件;
2、预制业务模型;
3、预制行业模板。
而预制的水准直接决定了低代码开发平台在降低学习、开发成本,缩短开发周期方面的表现,很容易理解,预制需要提前预测未来客户需求是什么、可能的变化。
同时,预制的成果是一个低代码开发平台的资产,以容联的CodeGPT为例,沉淀了15年的呼叫中心相关UI组件、数据模型、行业模板,是这个低代码的核心价值。
2.4.应用的范围
1、可视化页面搭建:最常见的,就是画布做页面;
2、可视化模型设计:很多厂家的元数据、数据模型等等;
3、可视化业务流程设计:最常见的是工作流等等;
4、可视化报表分析:最常见的是各种报表工具或BI工具;
5、可视化角色权限设计:角色权限的开发往往是各种业务系统的难点,可视化的难度也是很大的。
3、低代码的开发模型
低代码的模型如下图:
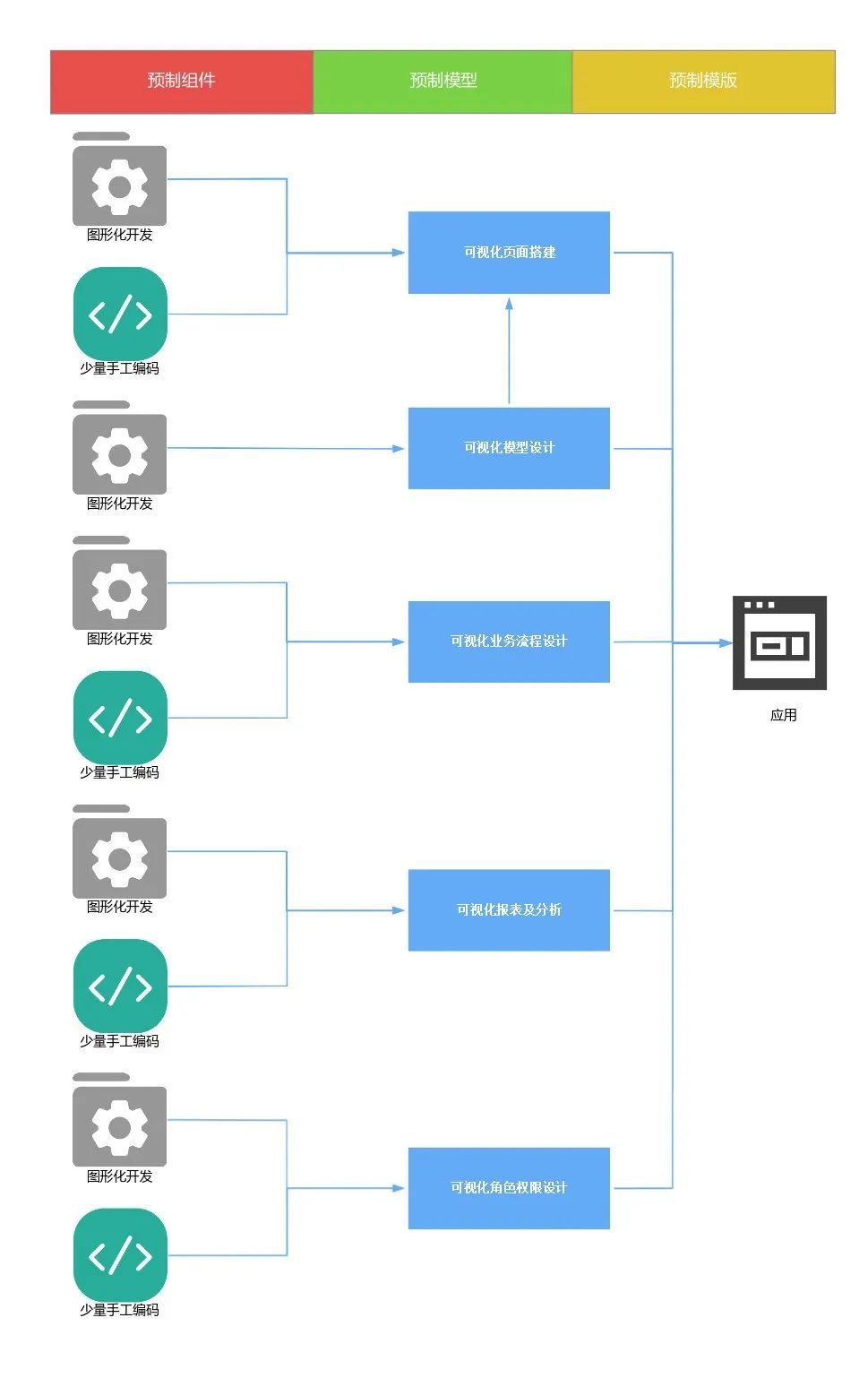
从上图可以看出,低代码应用,就是基于预制件(预制组件、预制模型、预制模板),由图形化开发+少量手工编码,通过可视化页面搭建、可视化模型设计、可视化业务流程设计、可视化报表及分析和可视化角色权限设计完成的。
02
认识大模型在开发上的作用
我们重新整理一下大模型的概念、能力,进而了解一下大模型在开发上的作用,最后,说明一下国内的大模型开发辅助方面领先的产品。
1、大模型的实现机制
大模型的实现上主要包括以下几个方面:
-
数据训练:大模型通常需要使用大量的文本数据进行训练,这些数据可以从互联网、书籍、文章等多种来源获取。通过这些数据的训练,模型可以学习到语言的语法、语义、上下文关系等特征。
-
深度学习:大模型通常采用深度学习技术,如循环神经网络(RNN)、长短时记忆网络(LSTM)、Transformer等,来实现对语言数据的建模。这些深度学习模型能够处理长距离的依赖关系,并捕捉语言中的复杂特征。 -
语言生成:在接收到输入文本后,大模型会基于概率分布生成接下来的词语或句子。这个过程可以通过采样或贪婪解码等方式实现。模型的生成能力使其能够创作文章、回答问题、翻译文本等。 -
注意力机制:注意力机制是一种能够使模型关注输入数据中重要部分的技术。在大模型中,注意力机制可以帮助模型更好地捕捉到上下文关系,提高生成的文本质量。 -
多任务学习:大模型通常采用多任务学习技术,同时训练多个任务,如语言建模、文本分类、机器翻译等。这有助于提高模型的泛化能力和性能。
2、大模型的基本能力
1. 语言理解:大模型通过训练可以理解和解释自然语言文本,能够回答问题、提供解释、理解指令和上下文含义等。
2. 语言生成:模型能够根据输入的上下文信息生成连贯、流畅的文本,例如撰写文章、生成对话、创作诗歌或故事等。
3. 文本摘要:大模型可以提取文本的关键信息,生成摘要,使得用户能够快速了解长篇文章或报告的主要内容。
4. 机器翻译:模型可以将一种语言翻译成另一种语言,帮助跨语言交流和理解。
5. 文本分类:大模型可以对文本进行分类,例如判断邮件是否为垃圾邮件、识别文本的情感倾向等。
6. 问答系统:模型可以用于构建问答系统,回答用户提出的问题,如在线客服、智能助手等。
7. 对话系统:大模型可以用来构建对话系统,与用户进行自然语言交流,如聊天机器人、虚拟助手等。
8. 语音识别:结合语音处理技术,大模型可以用于语音识别,将语音转换为文本。
9. 自动摘要:模型可以自动从长篇文章或视频中提取关键信息,生成摘要。
10. 文本生成:大模型可以生成各种类型的文本,如新闻报道、产品描述、电子邮件等。
这些能力使得大模型在许多实际应用中具有广泛的应用价值,如搜索引擎、推荐系统、自动化写作、智能客服、教育辅导等。随着技术的发展和模型的不断优化,大模型的性能和应用范围还将进一步扩大。
3、大模型在开发辅助上的作用
1. 代码补全:大模型可以预测开发者输入的代码序列,帮助快速完成代码编写。这可以减少开发者的输入时间,降低犯错率。
2. 代码审查:通过分析代码的风格和潜在错误,大模型可以帮助开发者识别代码中的问题,提供改进建议。
3. 错误诊断和修复建议:当软件出现问题时,大模型可以根据错误信息提供可能的故障原因和修复方案。
4. 文档生成:大模型可以自动生成代码的文档,包括API说明、代码注释等,帮助开发者理解和维护代码。
5. 自动化测试:大模型可以生成测试用例和测试代码,帮助开发者进行自动化测试,提高测试覆盖率和效率。
6. 代码搜索和重构:大模型可以理解代码的意图和结构,帮助开发者搜索特定的代码段或模式,并建议重构代码以提高可读性和可维护性。
7. 智能对话系统:大模型可以用于构建智能对话系统,帮助开发者与软件系统进行自然语言交互,获取信息、解决问题或进行反馈。
8. 需求分析和自动化代码生成:大模型可以理解自然语言描述的需求,自动生成相应的代码结构,减少手动编码工作。
9. 知识库构建和问答系统:大模型可以帮助开发者构建知识库,并提供自然语言查询支持,使得开发者能够通过提问获取所需信息。
10. 代码风格统一和规范检查:大模型可以识别代码中的风格不一致之处,并提供统一的风格建议,帮助维护代码规范。
大模型的这些应用可以显著提高软件开发的效率,减少人为错误,提升代码质量,同时也为开发者提供更多的智能化辅助工具。随着技术的不断进步,大模型在软件开发中的作用将会更加广泛和深入。
4、大模型开发辅助的领先产品
令人惊讶的是,国内大模型辅助开发的产品已经商业化了,请看下面的表格:

其中,百度的Comate在收费上非常有自信,没有免费版本,和阿里的通义灵码一样,支持更多的语言类型。
从功能上来讲,包含如下内容:
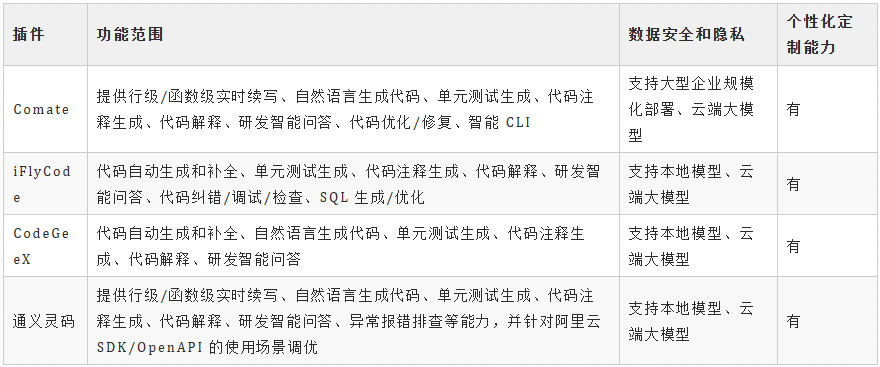
注意,这里在实时续写方面,只支持行级/函数级,距离类级、模块级、应用级还差得很多很多。
03
低代码面对大模型的挑战
然而,2023年的ChatGPT的发力,提出了“无需开发,说说就可以生成应用”,对低代码形成了降维打击。
低代码作为硬开发的终结者,马上要被大模型终结了。
1、低代码的瓶颈
低代码在构建的初期,往往业务复杂度较低,配置逻辑简单,需要的脚本也非常少,然而,经过一段时间的发展,客户应用复杂度的增加,导致低代码变得越来越复杂,表现在两个方面:
1.配置复杂度过高
现在的应用,配置项越来越多,菜单配置、权限配置、页面配置、控件配置、样式配置、接口配置、数据项配置、验证配置、逻辑配置…,虽然都是点击拖拽,在配置项过多的情况下,往往学习成本还是非常高的,不但要搞清楚每一个配置的作用,还要熟悉配置之间的关联,不是一个很简单的技能;
2.脚本复杂度过高
正如javascript在初期只是很小的集合,非开发人员就可以使用,只是配合前端展示的小脚本;然而,随着客户需求的不断提升和厂家之间竞争的日益加剧,javascript变得非常庞杂,react、vue等多种框架随之产生,很专业的开发人员才能掌握。
3.更低门槛的需求
低代码零代码门槛的不断降低,促使众多产品经理甚至最终非IT的用户需要参与到软件开发中。需求的驱动,让人们不能满足仅仅减少对硬编码开发者的依赖,而是要公民开发者能够主导软件的开发。
4.更敏捷的需求
在众多领域中,瀑布式开发彻底被抛弃,客户无法等到你通过各种文档确认需求,他需要通过微信文本甚至语音沟通表达自己的需求,很短的时间内就看到软件的效果。即使是少量的脚本也无法满足客户的这种及时性需求。
5.大模型的环境驱动
面对各行各业的IT技术的迅猛发展,更快、更易的人机交互模式不断提升,车载终端的语音交互已经普遍被接受,为什么我们就不能通过自然语言完成开发。
无论是ChatGPT,还是微软的Copilot,都能通过自然语言进行开发,不断向低代码提问:自然语言开发什么时候能可以用?
2、大模型与低代码的对比
现在我们做一个对比分析,如下图:

具体来说:
1、预制组件/模型/模板:这是低代码的核心资产,是大量人工实现的,包括行业专家的分析、客户的分析整理、程序员开发调试、测试工程师的查错、用户的使用改进;这些都是大模型无法达到的;
2、自然语言输入:这个是大模型的绝对优势,包括自然语言语义理解、基本推理能力等等,与低代码的鼠标键盘输入,学习成本自然极大降低;
3、丰富的代码参考:使用者在开发过程中,可以参考到全世界最优秀的同类代码,大模型可以预测你要写什么代码,确实能大幅提升效率,这一点低代码完全不能相比;
4、低代码配置项过多:虽然配置比开发简单很多,但是,当配置项多到一定程度、配置项之间的关联越来越多的时候,配置绝对不是一件简单的事情,学习成本还是很高的;
5、低代码的脚本开发难度:虽然脚本比代码简单,但是,有大模型辅助开发的时候,脚本就比代码难度大了,写个正则表达式看看,相信大多数程序员都会搜索一阵儿,更何况低代码开发者呢;
6、大模型还是开发,工作量还是大很多很多;
7、大模型生成代码,还是行级和函数级的,几乎无法形成一个页面,但是低代码完全可以完成一个CRUD页面的生成。
通过分析,大模型替代终结低代码,路还很远,不必恐慌。
但是,大模型的发展势头是让每一个人焦虑的,我们依然需要将大模型利用起来,为低代码提供有力地支撑,怎么做呢?
04
低代码大模型的架构
根据上面的分析,低代码的优势在于预制组件/模型/模板,大模型的优势在于自然语言理解、基本推理、海量代码的积累。
再分析,低代码更专业化,大模型更通用化。
从本质上来讲,低代码是对硬编码的转换,转换为行业的预制组件/模型/模板、脚本、操作指令,为了使用大模型硬编码的能力,我们将低代码专用的预制件、脚本、操作转换为硬编码,让大模型处理,大模型回应的硬编码的结果再转换回低代码的预制件、脚本、操作转换。
可以完美整合在一起,架构如下:
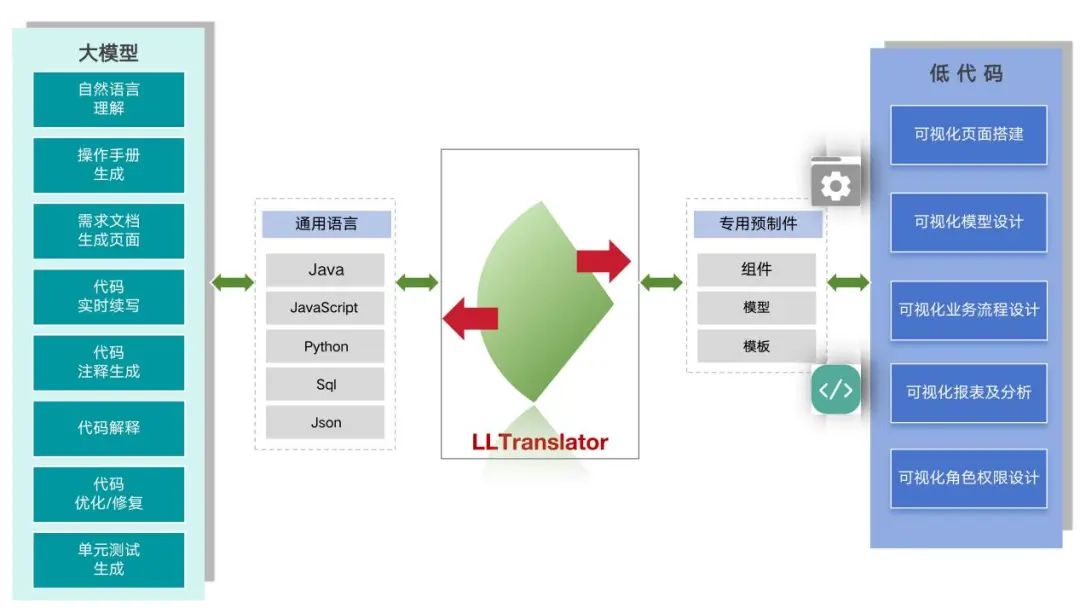
明确两个术语:
-
低代码提示词:用户在低代码开发平台输入的提示词;
-
大模型提示词:低代码开发平台向大模型发送的提示词。
1、大模型能力:大模型具备的能力包括自然语言理解、代码生成操作手册、需求文档生成页面、代码实时续写、代码注释生成、代码解释、代码优化/修复、单元测试生成;
2、通用语言:大模型的以上能力都是基于通用语言的,包括Java、Javascript、Python、Sql、Json等等;
3、低代码能力:低代码具备的能力包括可视化页面搭建、可视化模型设计、可视化业务流程设计、可视化报表及分析、可视化角色权限设计;
4、低代码输入输出:低代码是基于专用预制件(预制组件、预制模型、预制模板)、图形化开发、少量脚本实现低代码开发的;
5、LLTranslator:LLM&LowCode Translator是一个翻译器,是整个低代码大模型架构的核心,翻译器是双向的:
(1)To大模型:将预制组件、预制模型、预制模板和脚本翻译成通用语言,如javascript;
(2)To低代码:将通用语言翻译成基于预制组件、预制模型、预制模板的指令或脚本;
为了说明这个模型,我以智谱清言大模型举两个例子。
1、自然语言生成页面示例
1、用户在低代码开发平台通过自然语言输入需求,如下:
低代码提示词:请为我生成一个请假单界面,字段不超过5个。
2、硬编码转换:LLTranslator将硬编码语言和库的说明添加,转换为以下的大模型提示词:
大模型提示词:请为我生成一个请假单界面,字段不超过5个。用Python的基于TKInter实现,只需要代码,不用任何其它说明。
3、大模型返回如下代码:
import tkinter as tkclass LeaveRequestGUI:def __init__(self, root):self.root = rootself.root.title("请假单填写界面")self.create_widgets()def create_widgets(self):# 姓名self.name_label = tk.Label(self.root, text="姓名:")self.name_label.grid(row=0, column=0, sticky="e")self.name_entry = tk.Entry(self.root)self.name_entry.grid(row=0, column=1, sticky="we")# 学号/工号self.id_label = tk.Label(self.root, text="学号/工号:")self.id_label.grid(row=1, column=0, sticky="e")self.id_entry = tk.Entry(self.root)self.id_entry.grid(row=1, column=1, sticky="we")# 请假日期self.date_label = tk.Label(self.root, text="请假日期:")self.date_label.grid(row=2, column=0, sticky="e")self.date_entry = tk.Entry(self.root)self.date_entry.grid(row=2, column=1, sticky="we")# 请假原因self.reason_label = tk.Label(self.root, text="请假原因:")self.reason_label.grid(row=3, column=0, sticky="e")self.reason_text = tk.Text(self.root, height=5, width=40)self.reason_text.grid(row=3, column=1, sticky="we")# 提交按钮self.submit_button = tk.Button(self.root, text="提交", command=self.submit_leave_request)self.submit_button.grid(row=4, column=1, pady=10)def submit_leave_request(self):# 这里可以添加提交请假单的逻辑messagebox.showinfo("提交成功", "您的请假单已成功提交。")if __name__ == "__main__":root = tk.Tk()leave_request_gui = LeaveRequestGUI(root)root.mainloop()
4、转换为专用指令:LLTranslator通过语法分析,我们可以识别出代码中的关键信息,

6、低代码平台执行指令形成页面即脚本。

这里,核心技术难点就是将通用的Python语法转换为低代码的专用语法。
2、修改页面字段及功能
1、开发者在低代码开发平台中打开并选中请假单页面,如下图:
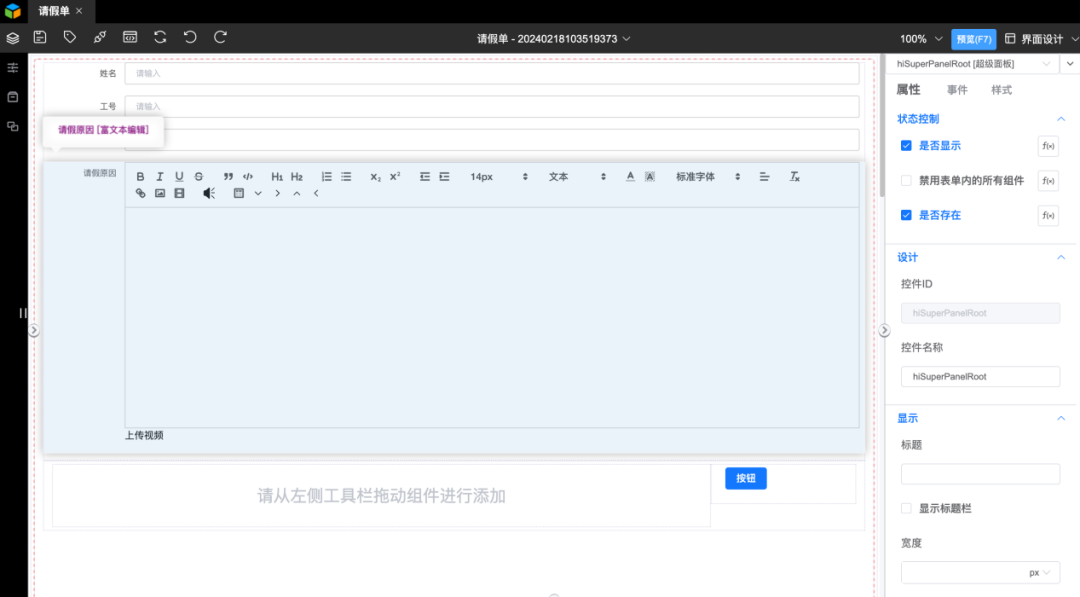
2、低代码开发者询问大模型,提示词如下:
低代码提示词:请增加两个字段,用于输入和显示审批过程。
以下代码,请增加两个字段,用于输入和显示审批过程。
import tkinter as tkclass LeaveRequestGUI:def __init__(self, root):self.root = rootself.root.title("请假单填写界面")self.create_widgets()def create_widgets(self):self.name_label = tk.Label(self.root, text="姓名:")self.name_label.grid(row=0, column=0, sticky="e")self.name_entry = tk.Entry(self.root)self.name_entry.grid(row=0, column=1, sticky="we")self.id_label = tk.Label(self.root, text="学号/工号:")self.id_label.grid(row=1, column=0, sticky="e")self.id_entry = tk.Entry(self.root)self.id_entry.grid(row=1, column=1, sticky="we")self.date_label = tk.Label(self.root, text="请假日期:")self.date_label.grid(row=2, column=0, sticky="e")self.date_entry = tk.Entry(self.root)self.date_entry.grid(row=2, column=1, sticky="we")self.reason_label = tk.Label(self.root, text="请假原因:")self.reason_label.grid(row=3, column=0, sticky="e")self.reason_text = tk.Text(self.root, height=5, width=40)self.reason_text.grid(row=3, column=1, sticky="we")self.submit_button = tk.Button(self.root, text="提交", command=self.submit_leave_request)self.submit_button.grid(row=4, column=1, pady=10)def submit_leave_request(self):messagebox.showinfo("提交成功", "您的请假单已成功提交。")if __name__ == "__main__":root = tk.Tk()leave_request_gui = LeaveRequestGUI(root)root.mainloop()
4、大模型的收到提示词后回应如下,其中,红色的为新增的两个字段,并且增加了审核的按钮。
```pythonimport tkinter as tkfrom tkinter import messageboxclass LeaveRequestGUI:def __init__(self, root):self.root = rootself.root.title("请假单填写界面")self.create_widgets()def create_widgets(self):self.approver_label = tk.Label(self.root, text="审批人姓名:")self.approver_label.grid(row=4, column=0, sticky="e")self.approver_entry = tk.Entry(self.root)self.approver_entry.grid(row=4, column=1, sticky="we")self.approval_label = tk.Label(self.root, text="审批意见:")self.approval_label.grid(row=5, column=0, sticky="e")self.approval_text = tk.Text(self.root, height=5, width=40)self.approval_text.grid(row=5, column=1, sticky="we")self.approval_result_button = tk.Button(self.root, text="查看审批结果", command=self.show_approval_result)self.approval_result_button.grid(row=7, column=1, pady=10)def show_approval_result(self):approval_result = "审批结果:请假批准"self.approval_text.delete(1.0, tk.END)self.approval_text.insert(tk.END, approval_result)if __name__ == "__main__":root = tk
5、LLTranslator收到大模型回应后,将Python代码通过语法树分析,转换为专用指令,专用指令如下:
action=createControl,controlType="textbox",controlName="name",label="审批人姓名",action=createControl,controlType="textarea",controlName="approval_text",label="审批意见:",action=createControl,controlType="button",controlName="show_approval_result",text="查看审批结果",event=buttonClick,script=’cm,”approval_text”,delete,1,-1’
这里核心技术在于将专用脚本转换为通用语言。
05
CodeGPT落地
笔者主导的CodeGPT已经实现落地,系统功能架构图如下:
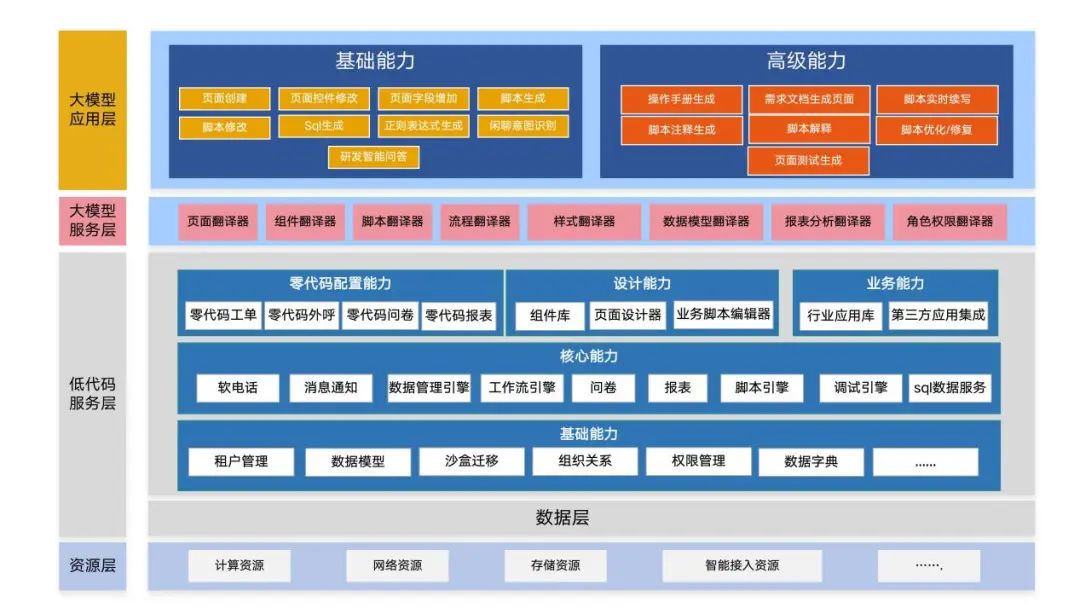
如上图,包括以下功能:
1)页面创建:自然语言创建页面,包括页面布局和页面功能脚本;
2)页面控件修改:自然语言修改页面控件的布局、风格、属性等等;
3)页面字段增加:自然语言请求大模型给出建议字段;
4)脚本生成:自然语言请求生成一段脚本实现特定功能;
5)脚本修改:给出原有的脚本,自然语言描述修改需求,大模型做脚本修改;
6)Sql生成:自然语言生成Sql;
7)正则表达式生成:自然语言生成正则表达式;
8)闲聊意图识别:拒绝开发辅助以外的提问;
9)研发智能问答:针对研发的开发问题的问答;
在发展的路径上,CodeGPT将继续完成以下功能:
1)操作手册生成:选择正在使用的低代码页面,大模型生成操作手册;
2)需求文档生成页面:向大模型提供需求文档,自动生成页面;
3)脚本实时续写:实时续写脚本,基本可以达到行级续写和函数级续写;
4)脚本注释生成:理解脚本,为脚本添加注释,提升脚本可读性;
5)脚本解释:理解脚本,并根据上下文,解释代码的逻辑、功能;
6)脚本优化/修复:优化和修复脚本;
7)页面测试生成:RPA整合,形成页面测试脚本;
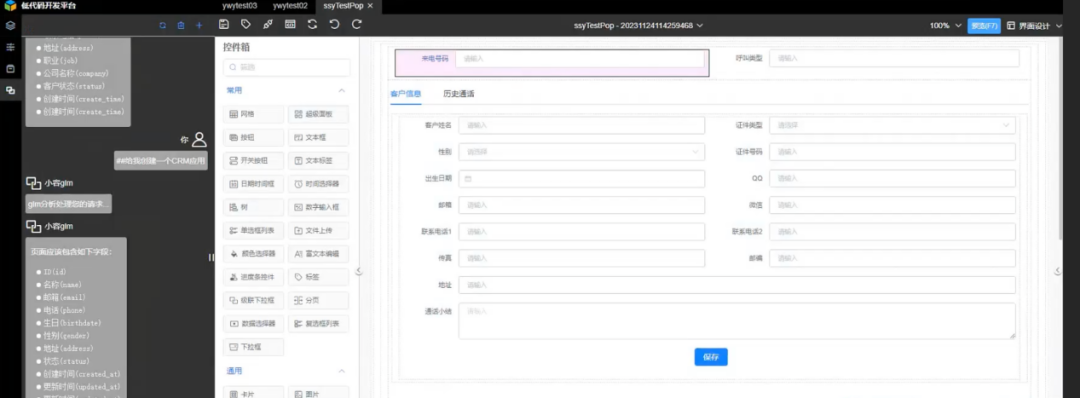
1、页面创建
自然语言创建页面,包括页面布局和页面功能脚本。
实现方式是用户自然语言输入需求,低代码开发平台通过翻译器将其转换为特定语言(如javascript或Python)的请求,大模型返回代码,翻译器将代码转换为低代码专用指令和脚本,形成页面。
如下图:
2、页面控件修改
大模型可以通过自然语言理解,提取出操作对象、操作属性、属性的各种参数,对控件进行各种形式的修改。
常见的包括:
1)增加姓名文本框的宽度;
2)将身份证号码输入框调到证件类型控件后面;
3)为电话号码输入框增加验证条件;
4)在地址输入框前面增加必填标识;
5)网格列表的第三个标题修改为“工单当前状态”;
6)…
3、页面字段增加
在低代码开发者已经完成了一个页面的开发,客户认为需要丰富输入字段项目,以便于满足更多的需求,低代码开发者可以通过自然语言请求大模型给出建议字段。
实现方式如下:
1)平台将低代码页面转换为通用语言页面,如javascript;
2)将javascript代码与提示词做格式化整个,提交给大模型;
3)大模型返回增加的代码表示的字段;
4)低代码将代码转换为低代码专用语言;
5)最终,增加字段在页面和脚本上。
4、脚本生成/修改
实现过程如下:
1)用户输入文本描述需要的脚本功能;
2)平台将现有页面的布局和脚本转换为通用语言;
3)平台将用户输入文本和通用语言进行格式化整合,发送给大模型;
4)大模型返回通用语言代码;
5)平台将通用语言转换为低代码脚本;
6)用户复制或插入操作完成。
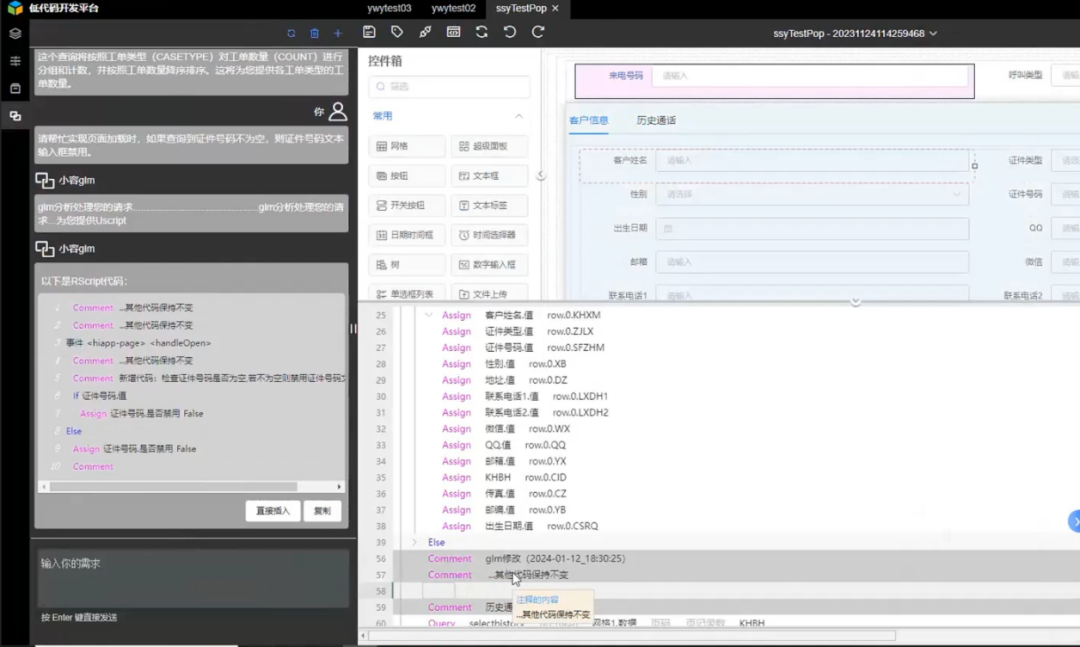
5、Sql语句生成
1)用户输入文本,描述需要生成的Sql语句的功能;
2)平台将文本输入大模型提取意图;
3)平台根据意图推荐多个数据库表供用户选择;
4)用户选择数据库表后,平台将数据库表结构和用户输入文本进行格式化整合后,发送到大模型;
5)大模型返回Sql语句,用户复制或插入到平台中。
6、正则表达式生成
正则表达式的生成,是每一个程序员经常用到的功能,但是使用过程还是比较繁琐的。
在低代码平台的实现过程如下:
1)用户输入文本描述正则表达式的需求;
2)平台组织提示词,发送到大模型提取意图;
3)平台根据意图检索低代码平台内置正则表达式(内置正则表达式准确性更高);
4)平台将内置正则表达式和用户输入文本组织新的提示词到大模型;
5)大模型返回正则表达式;
6)用户插入或复制使用。
7、闲聊意图识别
闲聊是我们经常遇到的,对于每一个Chat类的应用都是一样的。因此,需要对闲聊类的提示词,我们需要进行判断,如果是闲聊,做拒绝处理。
这一点虽然对于我们开发辅助的作用不大,但是是必备的,也是考验系统完整性的必要功能。
8、研发智能问答
9、操作手册生成
本程序是一款用于填写请假单的图形用户界面(GUI)程序。用户可以通过该程序填写姓名、学号/工号、请假日期和请假原因等信息,并提交请假单。
(2)操作步骤
打开程序:运行程序后,会出现一个名为“请假单填写界面”的窗口。
填写信息:
姓名:在“姓名”文本框中输入您的姓名。
学号/工号:在“学号/工号”文本框中输入您的学号或工号。
请假日期:在“请假日期”文本框中输入您的请假日期。
请假原因:在“请假原因”文本框中输入您请假的原因。
提交请假单:
点击“提交”按钮,程序会弹出一个提示框,显示“提交成功”,说明您的请假单已成功提交。
(3)注意事项
请确保您填写的信息真实、准确,以便程序能够正确处理您的请假单。
提交请假单后,请留意程序的提示框,以便了解请假单的处理情况。
若需修改请假单,可以重新打开程序,并输入相关信息进行修改。

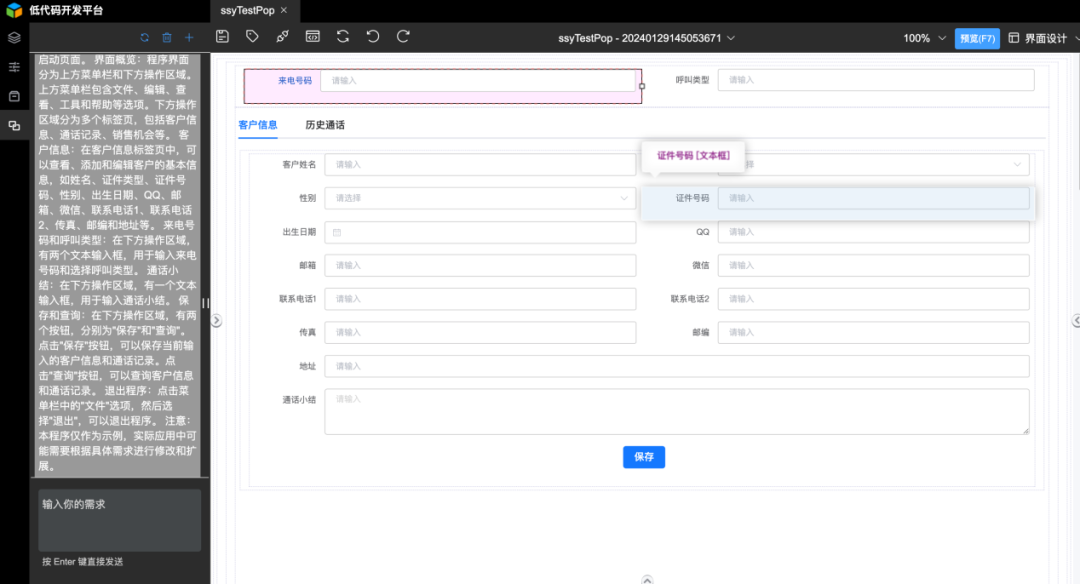
10、需求文档生成页面
输入你的需求
11.脚本实时续写
整体功能可以参考现有的四个国内辅助开发工具的能力。
实现方式上来讲,基本上是将低代码脚本转换成通用语言,大模型续写成通用语言,然后转换回低代码。
12.脚本注释生成
整体功能可以参考现有的四个国内辅助开发工具的能力。
实现方式上来讲,基本上是将低代码脚本转换成通用语言,大模型为通用语言添加注释,平台将注释添加到低代码脚本中。
13.脚本解释
整体功能可以参考现有的四个国内辅助开发工具的能力。
实现方式上来讲,基本上是将低代码脚本转换成通用语言,大模型对通用语言的代码进行解释,即对低代码脚本进行解释。
14.脚本优化/修复:
实现方式上来讲,基本上是将低代码脚本转换成通用语言,大模型对通用语言的代码进行优化或修复,平台对优化修复过的通用代码转换成低代码。
15.页面测试生成
1、用户输入测试需求;
2、平台将低代码页面翻译成通用语言代码如vue页面;
3、平台将用户测试需求叠加通用语言代码发送给大模型;
4、大模型生成基于Selenium的RPA测试脚本;
5、执行脚本RPA脚本完成测试。
06
结束语
从本质上看,低代码就是对硬编码的基于专业领域的封装抽象;大模型已经学习了几亿几十亿通用代码,可谓博大精深;构造一个双向翻译器,就可以将大模型的知识广度、分析深度引入到专业低代码领域;低代码开发者只需要提高领导力,就能大幅提升产能。
本文为投稿文章,作者/黄河
– END –
大佬观点
西门子低代码-王炯 | 西门子低代码-阮铭 | 微软-李威 | 微软-徐玉涛 | 葡萄城-李佳佳 | 葡萄城-宁伟 | SAP-陈泽平 | 华为-周明旺 | 华为云-董鑫武 | 钉钉宜搭-邵磊 | 轻流-严琦东 | 腾讯云微搭-骆勤 | 网易数帆-陈谔、严跃杰 | 百特搭-姜楠
用友-刘鑫 | 数睿数据-张超 | 奥哲-朱鹏喜 | 炎黄盈动-汤武 | 普元信息-孟庆余 | 得帆-李健达 | 瀚码技术-钟惟渊 | iVX-孟智平
Treelab-何浚炫 | 阿里-汪凤震 | 明道云-薛晨 | 上海斯歌-傅正斌
公众号后台回复【加群】


