









👉导读
👉目录
01
面向对象的分析与设计的原理包括以下 5 种概念。
-
对象/类:数据结构与作用于数据的方法或函数紧密结合或关联。这称为类,或对象(对象是基于类创建的)。每个对象执行一个独立的功能。它由其属性定义,即它是什么和能做什么。对象可以是类的一部分,类是一组相似的对象。
-
信息隐藏:保护对象的某些组成部分免受外部实体侵犯的能力。这是通过语言关键字实现的,使变量可以被声明为私有或受拥有类保护。
-
继承:类扩展或覆盖另一类功能的能力。所谓的子类有一整部分是从超类派生(继承)的,然后它有自己的一套函数和数据。
-
接口:推迟方法实现的能力。定义函数或方法签名而不实现它们的能力。
-
多态:用其子对象替换对象的能力。对象变量包含的不仅是该对象,还有所有的子对象的能力。
如果需要对面向对象的分析中异常处理的深入分析还需要对一些重要的术语进行解释和分析。
1.1 属性、方法、事件
-
属性:属性描述了对象的状态。例如,在一个汽车对象中,颜色、型号、最高速度等可以被看作是汽车的属性。在面向对象编程中,属性通常被表示为字段变量。通常情况下属性的名称一般是名词;
-
方法:方法描述了对象可以执行的操作。例如,在一个汽车对象中,启动、加速、刹车等可以被看作是汽车的方法。在面向对象编程中,方法通常被表示为对象的函数或过程。通常情况下方法名字是动词;
-
事件:事件是对象在特定条件下可以触发的行为。例如,当一个汽车对象的速度超过了一定的值,它可能会触发一个超速警告事件。事件通常用于处理用户的输入或其他交互行为。
不少开发者将属性和类的字段这两个术语化为等号,其实这个是不正确的。比如:一个汽车的生产日期和车龄,生产日期修改时,车龄也会随时变化,实现上就很有可能只用一个字段来存储。
class Car {public:void set_finish_time(std::chrono::system_clock::time_point t) { finish_time_ = t; }std::chrono::system_clock::time_point finish_time() const { return finish_time_; }int year() const {std::time_t now_c = std::chrono::system_clock::to_time_t(finish_time_);std::tm now_tm = *std::localtime(&now_c);return now_tm.tm_year + 1900;}private:std::chrono::system_clock::time_point finish_time_;}
上述 year 这个属性是通过计算出来的,是只读属性, finish_time 是读写属性。当然你也可以在增加一个 lunar_finish_time 这个读写属性用于通过设置农历的方式来设置,但最终都只会反应到 finish_time_ 这个字段上。
C++ 中缺乏对属性和方法的区分,属性和方法只都是通过成员函数来实现的,C++ 中对于属性的修改通常是通过与之对应的 Getter/Setter 来实现的。但对于 C++ 的影响后的语言,更多的是将属性和方法分开,如 VB.NET 中 Property Get/Set C# 中的 get/set,JavaScript 中的 get/set 关键字,Delphi 中 property...read...write 等。
Class CarPrivate _finish_time As DateTimePublic Property FinishTime() As DateTimeGetReturn _finish_timeEnd GetSet(ByVal value As DateTime)_finish_time = valueEnd SetEnd PropertyPublic ReadOnly Property Year() As IntegerGetReturn _finish_time.Year()End GetEnd PropertyEnd Class
通常情况下,使用属性时的自然语义是:
-
设置一个可写属性:
object.WritableProperty = newProperty,设置一个可写属性之后,object这个类的实例实际上发生了变化,可能会引发起多个字段的改变,但这个字段不一定对应到这个对象的某个特定的字段中。 -
读取一个可读属性:
myProperty = object.ReadableProperty,获取一个可读属性之后,object实际上不应该有任何的变化,故在 C++ 中一般可读属性都会标记为const。
而方法重要的代表这个对象的某种能力,或某种职责。比如汽车有速度的属性,当启动、加速、刹车就对应了这个对象的三种操作,而这些操作会引起属性的变化。
class Car {public:void Start() { set_speed(1); }void SpeedUp() { set_speed(speed() + 1); }void SlowDown() { set_speed(speed() - 1); }void set_speed(int v) { speed_ = v; }int speed() const { return speed_; }private:int speed_ = 0;}
这里来简单用一个表格归纳一下属性和方法的区别。
| 属性 | 方法 | |
|---|---|---|
| 引起实例状态的改变 | 获取属性值不会,设置属性会 | 绝大多数情况下会 |
| 名称约定 | 一般情况下使用名词 | 一般情况下使用动词 |
| C++ 中大小写约定 | C++ 使用 snake_case | C++ 使用 PascalCase |
| Java 中起名约定 | 使用 getXxx setXxx 进行区分 |
一般情况下使用动词 camelCase |
既然属性的修改和方法都有可能引起最终对象状态的变化,那么是不是有一种办法可以监听这种改变的。一种比较复杂的做法(不推荐)是将所有这种变化通过虚函数定义起来,并在变化前后都使用虚函数来触发。子类需要重写这个虚函数,从而实现对这些改变前或改变后的状态做出改变。例如:
class Car {public:void Start() { set_speed(1); }void SpeedUp() { set_speed(speed() + 1); }void SlowDown() { set_speed(speed() - 1); }void set_speed(int v) {OnBeforeSpeedChange(speed_, v);speed_ = v;OnAfterSpeedChange(speed_);}int speed() const { return speed_; }virtual void OnBeforeSpeedChange(int old_speed, int &speed) const {}virtual void OnAfterSpeedChange(int speed) const {}private:int speed_ = 0;}
但这样一种分析与设计中不太符合对于考察对象 Car 的设计。因为对于一个车辆本身而言,在速度改变前、在速度改变后并不一定属于车辆或车辆这个子类的职责。
很多现代语言都对这样的一种事件驱动的场景做出了语言层面的扩展。比如 VB.NET 中的委托用于定义一个事件的签名(类型),再定义事件这个对象。那么当属性改变时,目标对象就可以直接发起这个委托的事件。
' 定义委托(函数签名)来保证某个对象可以以这样的委托来触发事件Delegate Sub BeforeSpeedChange(ByRef sender As Object, ByVal oldSpeed As Integer, ByRef speed As Integer)Delegate Sub AfterSpeedChange(ByRef sender As Object, ByVal speed As Integer)Class CarPrivate _speed As Integer' 定义一些事件用来表示“车”这个对象有可能在某些状态变化时触发这些时间,并按照委托定义的签名来触发Public Event OnBeforeSpeedChange As BeforeSpeedChangePublic Event OnAfterSpeedChange As AfterSpeedChangePublic Property Speed() As IntegerGetReturn _speedEnd GetSet(value As Integer)' 触发速度改变前事件,注意这里的 value 是按引用传递的,' 即事件处理函数可以修改这个 valueRaiseEvent OnBeforeSpeedChange(Me, _speed, value)_speed = value' 触发速度改变后事件,注意这里的 _seeed 是按值传递的,' 即事件处理函数不可以修改这个 speedRaiseEvent OnAfterSpeedChange(Me, _speed)End SetEnd PropertyPublic Sub Start()Speed = 1End SubPublic Sub SpeedUp()Speed += 1End SubPublic Sub SlowDoup()Speed -= 1End SubEnd ClassModule ModuleExampleSub Main()Dim car As New CarAddHandler car.OnBeforeSpeedChange,Sub(ByRef sender As Object, ByVal oldSpeed As Integer, ByRef speed As Integer)Console.WriteLine("Car change from {0} to {1}", oldSpeed, speed)End SubAddHandler car.OnAfterSpeedChange,Sub(ByRef sender As Object, ByVal speed As Integer)Console.WriteLine("Car change {0}", speed)End Subcar.Start()End SubEnd Module
上述代码中 Car 对象和事件处理函数就完全解耦了,通过 lambda 表达式中的 sender 拆箱之后获得被执行对象的发起者。
假如我们使用面向对象的分析与设计来分析 Car SpeedLimiter—— 一个汽车限速装置的,这样系统的设计。我们应该是怎么设计的呢?
-
Car中定义属性Speed用于定义当前行驶过程的速度; -
Car中使用SpeedUp方法用于加速操作; -
声明委托
BeforeSpeedChangeAfterSpeedChange用于签名当速度改变前后进行的事件; -
Car在属性Speed中触发委托调用; -
SpeedLimiter中实现BeforeSpeedChange用于超速的拦截和告警; -
程序启动时分别创建
CarSpeedLimiter; -
将
speedLimiter的BeforeSpeedChange方法注册到car的事件中。
那么,Car SpeedLimiter 通过定义的委托就实现了触发→调用这一机制的解耦。如果使用传统的虚函数来驱动,那么就必须为每个需要限速的 car/bike/motocycle 之类的全部编写一把限速逻辑。
这样通用的设计,目前只有 .NET(VB.NET、C#、C++/CLI) 在语言层面实现了这一设计。
1.2 资源获取即初始化
资源获取即初始化(RAII)是一种在几种面向对象、静态类型的编程语言中使用的编程习惯,用于描述特定的语言行为。在 RAII 中,资源的持有是类的不变式,并与对象生命周期绑定。资源分配(或获取)在对象创建(特别是初始化)时由构造函数完成,而资源释放(解除)在对象销毁(特别是最后处理)时由析构函数完成。换句话说,资源获取必须成功才能使初始化成功。因此,资源保证在初始化完成和最后处理开始之间被持有(持有资源是类的不变式),并且只有当对象存在时才被持有。因此,如果没有对象泄漏,就不会有资源泄漏。
RAII 最初起源于 C++,与之最为关联,但也在 D、Ada、Vala 和 Rust 等语言中有所应用。该技术主要由 Bjarne Stroustrup 和 Andrew Koenig 在 1984-89 年间为 C++ 的异常安全资源管理开发,术语本身由 Stroustrup 首次提出。
RAII 作为一种资源管理技术的优点在于它提供了封装、异常安全性(对于栈资源)和局部性(它允许获取和释放逻辑被写在彼此旁边)。封装是因为资源管理逻辑在类中定义一次,而不是在每个调用站点。对于栈资源(在同一范围内被获取和释放的资源),通过将资源绑定到栈变量(在给定范围内声明的局部变量)的生命周期,提供了异常安全性:如果抛出一个异常,并且有适当的异常处理机制,当退出当前范围时,唯一将被执行的代码是在该范围内声明的对象的析构函数。
RAII 由于在析构函数中自动释放获取的资源,无论正在使用的特定机制是什么,都有一个运行时保证析构函数会在对象实例消失之前被调用。因此,它应该始终被使用。与此同时,当对象消失时,它的成员也会消失,每一个成员在退出时都会执行它的析构函数。所以,如果这些成员对象实现得正确,就没有必要做任何事情。
#include <fstream>#include <iostream>#include <mutex>#include <stdexcept>#include <string>void WriteToFile(const std::string& message) {// 一个全局的对象用于让读取文件互斥的进行static std::mutex mutex;// 在访问文件之前锁定互斥体,这样就保证了下述的代码将在在多线程访问时不会穿梭执行std::lock_guard<std::mutex> lock(mutex);// 打开文件std::ofstream file("example.txt");if (!file.is_open()) {// 这里抛出异常会跳出 WriteToFile 函数区域,RAII 特性保证 file/lock 都会被析构throw std::runtime_error("unable to open file");}// 输出数据到文件中file << message << std::endl;// 当 file 离开作用域是会被析构,析构时会自动关闭打开的文件,无论是不是因为异常而离开作用域// 当 lock 离开作用域时会自动解锁互斥体(通过 lock_gard 的析构函数),无论是不是因为异常或正常返回}
如果我们按照领域服务的逻辑 UML 来编写代码,使用 RAII 思想来编写将做的非常自然。
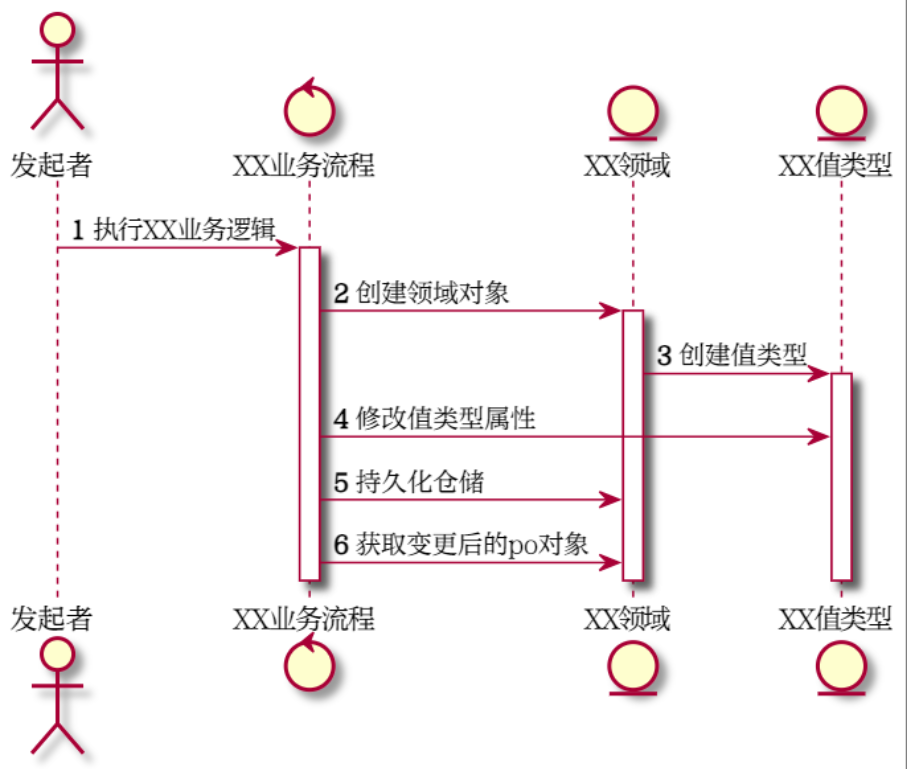
比如在修改值对象属性这一步骤出错了(例如车速太快,翻车了)。那么正常人类对于这样不是有特殊的逻辑的设计的程序,会根据 RAII 的思想将会执行以下步骤:
-
值对象(例如
CarSpeed)由于设置一个异常的值(例如:car.speed().set_speed(100000);),从而引发异常; -
值对象因为不会存在一个 100000 数字的车速,导致此对象被析构;
-
领域对象组合了其中的值对象,由于 RAII 思想,
car组合的car_speed也不再有效,那么car也将被自然的析构; -
由于业务流程创建了
car被析构掉,所以也不能继续执行持久化领域对象到仓储及其后续的步骤; -
最终由框架来兜底异常处理(上报错误码、监控、或重启进程)。
这一切的做法都可以将 UML 序列图最大程度的映射到实现代码中,因为异常思想就是包含在面向对象的分析与设计中的。在设计序列图时,只需要关注当前领域能够处理的异常才是最佳的实践。比如上图中,如果业务流程能够处理修改值对象属性异常,那么就可以拦截到值对象对象的异常,此时领域对象还没有修改,也不会消亡,从而进行额外的操作。
1.3 符合面向对象的异常计思路
某业务一直都有使用领域设计驱动和面向对象的分析与设计两种思想来分析业务。但由于某些遗留的思想,很多开发者选择使用返回错误码这样一种 C 语言时代的思考方式来编写业务代码。给个简单的例子就能看看写出来的代码有多丑陋了。
class AmountDomain {public:int Plus(const AmountDomain &other) const;int Minus(const AmountDomain &other) const;int Set(int amout);int IsValid() const;const std::string &last_error() const { return last_error_; }private:int amount_ = 0;std::string currency_ = "RMB";std::string last_error_;};
-
所有的类都有 last_error属性用于表示最后一个操作的错误信息,即这个对象为什么会坏掉,由于要保存最后一次坏掉的状态,这个对象依然不能被析构 -
所有的类都有 int IsValid() const成员方法用来判断这个对象是不是坏掉,并且判断是不是坏掉的方法还有可能返回错误 -
所有的操作符重载都不能使用 operator+/-都有可能出现错误,所以必须要返回一个错误码来表示操作结果 -
这个对象坏掉还是会继续存在(不符合 RAII 设计原理),因为里面还是有数据,还有可能有上次操作的错误码和错误信息。
if (auto ret = obj.Operate(arg...); ret) {Log("日志日志日志");Oss("报报报");return ret;}
虽然聪明的人觉得可以用宏简化这些符号,但每一层的上报和日志监控考验着代码编写者巨大的耐心和毅力,也挑战者代码审阅者爆裂的心态,最终让代码工作者迷失在无尽的上报、日志、监控上。
然而如果要对控制信息进行升级(比如级联返回的不再只有错误码,还有控制码,调用帧,错误上下文)怎么办呢,只能再搞个类似 errno 的错误对象来全局存储,这样一搞某些函数返回只有错误码,有些函数又写了全局变量 errno,一个本来明明很好理解的错误信息被硬生生的割裂到两个地方放置。
更严重的是,定义一个返回码,你压根就没有能力约束主调方是不是真正判断了返回码(如果非要有人说 [[nodiscard]] 那我也没办法,毕竟这也是习惯的问题)。正如更高级的语言中所描述的最佳实践一样:
Exceptions ensure that failures don’t go unnoticed because the calling code didn’t check a return code. 你应该抛出一个异常,而不是返回一个错误码。因为引发一个异常,对于那些没有检查返回码而继续的人,也不会走到后面的正确的逻辑。
框架设计者应该意识到,异常不是某种语言的特性,而是一种思考的范式。这种范式是一种面向对象的设计的核心思想的延伸——我这个领域对象只能处理我领域内的事物,领域内的事物包括了属性、方法、事件,也包括了面向对象的任何一种在执行代码时出现的逻辑错误——异常:
-
领域调用某知识域或值类型的操作可能会引发异常:
-
如果是领域内可以处理这个知识域或值类型的异常(如某次扣款扣成了负数,对于金额这个值类型可能就出现异常了,如果我的系统可以处理赊贷,那么我就可以转换成我领域的状态为赊贷,并设置赊贷金额),那么我将其捕获,并完成错误恢复。
-
如果这个领域内的异常不属于能处理的,那么我就转发,交由上层来处理。
-
如果我这个领域内某些操作引发了异常,那么我就抛出这个异常,交由上层来处理,如果最终上层也没人处理那么我这个领域对象自然销毁(RAII 的设计模式)。
-
如果流程服务无法处理领域逻辑的异常,直接终止流程,领域对象销毁。
1.4 小结
02
如果作为一名框架的作者,首先不应该是避免使用某些语言的特性,而应该思考如果使用方使用了这些特性会造成那些问题,如何规范的使用这样的特性。
2.1 思辨地看待使用错误码
优点 1:明确性
__LINE__ 这样的宏来解决(简直是可恶至极)。CURLcode 或 std::error_code 才是真正实践了明确性这样一个特点。优点 2:兼容性
-
构建系统:采用 Bazel 作为后端代码构建工具(Bazel 是一个面向大型项目的强大构建工具,通过其高效的增量构建、多语言支持和分布式能力,帮助开发人员管理复杂的软件构建过程,并提供可靠的构建结果)。 -
C++ 工具链:统一使用 GCC 7.5.0 作为构建工具; -
第三方开源库:收归到统一代码仓库,统一管版本管理; -
运行环境:统一使用腾讯云 tlinux 2.6 发行版作为线上的运行环境。
优点 3:性能
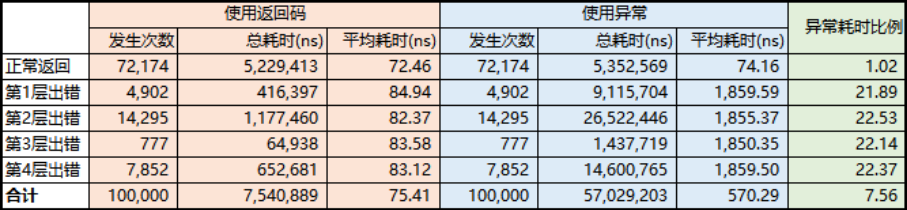
-
在编写业务逻辑中,悲观分支和乐观分支的概率并不是相等,我们选择了工作中比较极端的情况(分别有 0.95 0.85 0.99 0.9 的概率走向乐观分支,但事实上悲观分支的概率要远大于乐观分支),通过评测结果发现只有 10 倍的性能损耗。 -
目前的业务逻辑中,一次网络请求的耗时大约是 2ms,一次 Protobuf 序列化大约是 10μs,使用异常或使用返回码来实现异常控制的时间几乎可以忽略不计,只要我们保持在编写 CPU 密集型时不要使用异常,即可完美规避异常的开销带来的耗时的问题。
-
某些开发者可能会拿悲观分支做 DDoS 攻击,因为悲观分支的耗时要比乐观分支耗时高 25 倍。首先悲观分支需要通过外网构造请求悲观分支的请求,此时首先收到请求会是接入层,接入层按照商用系统的规范一定会配置分布式频率限制组件,构造悲观分支的 DDoS 攻击根本很难突破分布式频率限制组件,另外大多数 API 都需要配置 AccessToken 访问凭据,如果没有足够多的访问凭据,构造异常数据包很快就会把坏人的配额用完。同时频率限制和额度限制的组件比悲观分支使用异常耗时高 4~5 个数量级,完全不会因为使用异常而感觉到处理有耗时中的波动。
缺点 1:易用性
// lib_component 代码提供方 LIBint foo_in_lib() {if (/* xxx */) return LIB_ERROR;// ....return 0;}// exe_business 代码提供方 BIZint foo_in_exe() {if (foo_in_lib()) { return MY_TRANSLATED_ERROR; }return 0;}// lib_framework 代码提供方 INFRAint foo_in_framework() {auto ret = foo_in_exe();if (ret == LIB_ERROR) {// 重试或换机重试之类}return ret;}
由于 BIZ 根本就没意识到 LIB_ERROR 会被 INFRA 理解为换机重试,所以 BIZ 会直接转义一个自己能够理解的,上报可以监控到的错误,可以被运营的错误码。但 INFRA 收到 MY_TRANSLATED_ERROR 后因为并不带有换机重试的语义所以丧失了 LIB_ERROR 传播的语义。
虽然我们可以把所有的返回码全部修改为一个全新的对象例如某框架的 MeshRet 其中包含了控制信息,但现在错误码的陋习已经深深的印刻在每个看起来不那么专业的伪 C++ 程序员心中,就算要推广 MeshRet 需要将所有的返回 int 的函数全部修改为 MeshRet 其工作量也非一般。
由于上述复盘进而推演出的错误码解决方案也漏洞百出。
int ret = secure::SafeKeyEncrypt(kMyProductId, kMyRuleId, input, output);if (ret != 0) {int error_type = SafeKey_GetErrorType(ret, kSafeKeyCryptCmd_Encrypt);if (error_type == kSafeKeyErrorType_System) {//通用加解密服务瞬时过载,需要换机重试,错误码务必传回至最顶层接口返回码return COMM_ERR_SAFE_KEY_AGENT_SYS_ERR;} else {//其他逻辑失败,按需处理}}
因为还是使用错误码这样一种方案,增加一个 SafeKey_GetErrorType 的转义逻辑,按照正常人的想法,肯定是对于某些特定的错误码,返回 kSafeKeyErrorType_System 即判断需返回换机重试,因为绝大多数加解密在正常的情况下异常都是应该是确定的,但研读过 SafeKey_GetErrorType 代码就发现,这个函数只是将几个极少数的错误码视为非系统错误,其他全部要求你换机重试。
结果是业务方几乎不会在所有 MMNewDataTicket_CommEncrypt 时去判断,而是在所有函数的总入口加这样一段逻辑。最终将所有的业务逻辑错误全部被转义成换机重试!
int ServiceDispatch() {int ret = dispatch.CallMethod();if (ret!=0) {// 但查看代码之后实际的逻辑是 !!只有某些特殊的错误码会被透传,其他不认识的全部转义的换机重试!!int error_type = SafeKey_GetErrorType(ret, kSafeKeyCryptCmd_Encrypt);if (error_type == kSafeKeyErrorType_System) {// 通用加解密服务瞬时过载,需要换机重试,错误码务必传回至 svrkit 接口返回码return COMM_ERR_SAFE_KEY_AGENT_SYS_ERR;}}return ret;}
缺点 2:可读性
-
框架开发者:一般承担的职责是与业务无关的,和操作系统或通用资源打交道的开发者,他们专注于在业务无关的性能优化、行为统一、等基础的能力; -
业务发开着:基本上就是将复杂的领域逻辑转换为机器所能正确执行的代码,占我们开发者的绝大多数; -
组件开发者:通常是在特定非业务领域制作通用型能力的开发者(如统一加解密、HTTP 调用、频率限制等),在框架的基础上收拢一般型专用能力的开发者。
-
除非我想知道,否则我根本就不关心你到底是怎么错了:根据 RAII 的思想,如果流程中某个节点出错了,异常的对象会被析构掉,而这些所谓的程序异常根本就不会在 UML 序列图中表现出来。 -
如果你出错了,要告诉我错在哪儿:因为我可能会对组件的特定行为进行兜底或业务异常处理。因为这些业务异常是真实反应在业务建模中的序列图中的。 -
框架开发者和组件间的协作,不要让业务知道:什么换机重试,服务器调权啥的,业务方根本不想知道,业务方只对业务逻辑负责,即:只对我能够处理的异常负责。
缺点 3:一致性
-
错误码非常宽泛:具体表述大家都懂吗? -1表示系统错误、网络错误,但真的是这样吗? -
错误码滥用: -1表示系统错误,但其实根本就是逻辑错误,只是当时偷懒并没有找一个可以可以合理存放错误码。 -
毫无意义的收敛:曾经某个版本的生成器生成的代码中将所有的 RPC 调用的全部收敛成返回值 -1,本来可以从负数错误码知道是哪个错误(路由不存在、过载拒绝服务、端口未打开),结果全部收敛到 -1,上层根本无法判断出下一步的操作。 -
权限职责未划分:全局一个错误码文件,虽然可以在一定程度上解决错误码可能分配重复的问题,如果是超大规模的系统,那么每次申请错误码,变更说明信息将成为一个冲突极高的操作,业务开发很有可能在编写到某个代码时才发现需要对此类异常进行运营(如统一发生次数、根据商户号聚合统计、配置告警等),此时就会尝试分配一个错误码来对此运营需求进行开发。
-
根据领域驱动建模划分错误码:再分配错误码之前,需要根据领域驱动建模来确定系统子域,然后再登记模块。每一层级都有管理员和操作者,操作者有权限在某个模块下分配错误码并定义错误码的描述和枚举名。这样就保证了分配的错误码的唯一性,也解决的错误码管理上的权责问题。不过上述划分我在一定程度上还是保留一些意见: -
无法做到对公共组件的错误码进行划分:比如构造一个数据库访问库,里面一些错误码,如插入时主键冲突,要如何登记在错误码系统中,这个组件并不属于任何一个业务系统或子域,而使用者在使用这些库时,应该进行错误码收敛,而对于这样的库的错误码在脱离业务做运行时的错误码运营也是几乎没有意义的。(很有可能在插入一个主键冲突的记录时,更换一个新的主键再次插入),有可能在业务逻辑的,组件的异常恰好是正常的业务逻辑。 -
逻辑和实现颠倒:在编写业务逻辑时,常常会出现一个疑惑,就是模块某些时候需要根据快慢、权限、场景等隔离部署,在目前的系统中,这些模块会对应不同的名字,比如 mmsomebizslowreadmmsomebizslowwritemmsomebiz4openapi但在业务分析时,这些模块还没有被划分开(业务分析只对业务进行分析,不对实现进行干涉),如果需要对错误码所针对的分支异常进行运营,理论上来说应该在业务分析时,某些错误码就应该被指定下来,赋予相应的场景和对应的描述,但目前系统中不存在这样的一种申请操作。我认为在对错误码建模时,就应该考虑子域和错误码是 1 对多的组合关系,而模块和错误码是多对多的关联关系,但错误码又耦合了运营的职能,如果错误码和模块是多对多的关系,又不能从全局唯一的错误码的监控中了解某个模块的健康状况。 -
错误码头文件自动生成统一管理:当每次有错误码变更时,错误码的枚举文件会自动被生成并推送到某个特定的代码仓库中,且这个代码仓库不允许被任何人工修改,只能通过自动生成工具修改。这样就在一定程度上杜绝的错误码滥用的问题(但在某些模块中你使用其他模块的错误码也拿你没办法)。 -
错误码和契约系统联动:当制定契约时,错误码需要被关联到具体某些接口中,这样是的每一个错误码都有具体的应用的场景,而且是可以被阅览和运营的,这样杜绝了宽泛的错误码,错误码系统做得足够简单的稳定,使得分配错误码成为一个低成本的事情,开发者认为绞尽脑汁的去想一个错误吗还不如简单的在系统中操作一下生成一个枚举来的方便。 -
制定错误码收敛和转发规则: -
调用异构系统的时(如 kv、libcurl、dal_set)或调用跨系统的服务时,需要收敛错误码,即对每一次调用都申请一个新错误码,而非直接将原来组件的错误码或异常直接进行转发,这样就可以从这个错误码的监控运营中了解某个具体业务逻辑的异常发生的状况,从而做的精确的告警,定位到哪个用例出现了异常 -
在同个系统或子域内直接服务间调用,转发上一级从错误码,除非遇到了异常自己可以处理,否则不需要重新申请错误码或转义错误码。这样做的目的其实和 C++ 异常中的 try...catch...类似——我能处理我能处理的,否则就交给上一级能够处理的来完成。
缺点 4:对自然语言的破坏
// 某个金额class Amount {public:Amount(int money_fen = 0) : money_fen_(money_fen) {// 这里我们业务规定金额不能为负数if (money_fen_ < 0) {throw std::logic_error("Money must greater than zero.");}}// 支持运算符重载对金额进行比较bool operator<(const Amount& other) const { return money_fen_ < other.money_fen_; }bool operator<=(const Amount& other) const { return money_fen_ <= other.money_fen_; }bool operator>(const Amount& other) const { return money_fen_ > other.money_fen_; }bool operator>=(const Amount& other) const { return money_fen_ >= other.money_fen_; }bool operator==(const Amount& other) const { return money_fen_ == other.money_fen_; }bool operator!=(const Amount& other) const { return money_fen_ != other.money_fen_; }// 注意这里的 +/- 运算符是而可能会抛出异常的,因为有可能隐式转换到一个非法的 Amount 实例Amount operator+(const Amount& other) const { return money_fen_ + other.money_fen_; }Amount operator-(const Amount& other) const { return money_fen_ - other.money_fen_; }// 重写转换成数字操作字operator int() const { return money_fen_; }private:int money_fen_ = 0;};// 用户账户class Account {public:const Amount& amount() const { return amount_; }Amount& amount() { return amount_; }void set_amount(const Amount& v) { amount_ = v; }void set_amount(Amount&& v) { amount_ = std::move(v); }private:Amount amount_ = 0;};int main(int argc, const char* argv[]) {Account a;a.set_amount(100);Amount bill(200);a.amount() = a.amount() - bill;return 0;}
a.amount() = a.amount() - bill; 这样的语句。而这样的语句是由业务逻辑分析而来的,而非程序员空想的。-
我们需要设置账户的金额属性为当前自己金额和账单金额的差值。 -
而金额是不是小于能 0,这个领域合法性只是由 Amount这个值类型决定的,而不是领域Account决定的。 -
如果业务序列图没有给出异常处理方案,那么 Acount a将在析构时销毁,a中的金额不会变成负数,因为不存在一个Amount对象中money_fen_是负数。
// 正确的使用错误码的示例代码// 注意由于使用了错误码,所以 C++ 中的运算符重载也不能使用了,只能使用 Minus 来代替int main(int argc, const char* argv[]) {Accout a;if (int ret = a.set_amount(100); ret) return ERR_INVALID_AMOUNT;Amount bill;if (int ret = bill.set_money_fen(200); ret) return ERR_INVALID_AMOUNT;Amount remain = a.amount();if (int ret = remain.Minus(bill); ret) return ERR_INSUFFICIENT_AMOUNT;Account tmp_a = a;if (int ret = tmp_a.set_amount(std::move(remain)); ret) return ERR_SET_AMOUNT;a = std::move(tmp_a);return 0;}// 然而更多的开发者可能会这么来完成int main(int argc, const char* argv[]) {Accout a;if (int ret = a.set_amount(100); ret) return ERR_INVALID_AMOUNT;Amount bill;if (int ret = bill.set_money_fen(200); ret) return ERR_INVALID_AMOUNT;// 这里将实际上分析中的资金金额的业务逻辑规则前置到流程服务了if (a.amount().money_fen() < bill.money_fen()) {return ERR_INVALID_AMOUNT;}a.amount().Minus(bill.money_fen());}
-
我们应该很自然的想到,为了避免在相减时出错,在业务流程 main中来做 amout 和 account 的判断,如果发现 amout 大于 acount 中的值,就会返回一个错误码。 -
但我们之前在设计分析序列图时,认为资金数额不能为负数是资金这个对象的一个业务规则。即能不能相减不是由流程服务 main 来决定的,而是应该在相减之后由导致违反了资金金额为负数这个业务规则导致的异常。 -
若未来我们需要在分析序列图中对资金金额不能为负数这一业务规则做调整(比如调整为允许 -100 元小额赊账),那么由于实际上业务开发将这个原本属于资金金额的业务规则实现在流程服务中,最终很有可能导致修改遗漏。 -
为什么开发者不会选择创建个资金金额的这样一个对象呢,因为为了不使用异常,所有的对象都必须增加一个完整性的状态,对每次操作这之后都需要对这个对象的正确性进行检查,而为了保存这个有效性的属性,所有的对象将不会遵从 RAII 的思想,因为你完全可以构造出一个不合法的对象使得这个对象的完整性状态为 false
缺点 5:强制检查
[[nodiscard]] ,导致编写代码时对于一些自认为不重要的代码缺少对错误码的检查和传播,此编写代码会造成严重的问题。[[nodiscard]],所以并不是有很多开发者会留意到这个情况。其实应该对于所有的对象写修改状态的操作都必须添加 [[nodiscard]] 。但目前很多代码还是使用 C++11 编译的,并不支持 [[nodiscard]] 属性标记。int foo(const SomeRequest &req) {SomeDomain d(req.domain_po());CHECK_RET(d.IsValid());CHECK_RET(d.StartTransaction());d.EnsureDone();if (auto ret = d.FinishTransaction(); ret) {d.RollbackTransaction();return ret;}return 0;}
EnsureDone RollbackTransaction 是没有进行检查的,但细心的代码审阅者会询问,为什么这带个函数不检查返回值?而其他的代码却检查了返回值。EnsureDone 可能发生错误,为了保持兼容性,我不得不将返回值从 void 修改为 int,放弃增加 [[nodiscard]],以前调用方的代码就可能因为改动而产生异常。如果我们保持使用异常的思维,认为所有调用(包括构造函数、设置属性、调用方法都有可能发生异常),那么就能简单的避免强制检查带来的问题。void foo(const SomeRequest &req) {// 由于使用了异常,也就不需要使用 IsValid 进行检查,因为构造即初始化,不正常的对象就不能构造出来SomeDomain d(req.domian_po());// 开始事务处理,如果开始失败,那么 SomeDomain 会被自动析构,保证资源的释放d.StartTransaction();// 在正式开始前,定义一个 defer 清理函数用于非正常终止时回滚操作// 目前 std::scope_exit 还只是存在 TSv3 阶段 https://en.cppreference.com/w/cpp/experimental/scope_exit// 暂时使用 BOOST_SCOPE_EXIT 代替// 或使用 polyfill https://github.com/offa/scope-guardbool need_rollback = true;BOOST_SCOPE_EXIT(&need_rollback) {// 注意 RollbackTransaction 应该必须保证最终成功并 nothrowif (need_rollback) d.RollbackTransaction();}BOOST_SCOPE_EXIT_END// 安全的调用其他方法或设置其他属性,因为失败时会执行 defer 中的代码块进行资源保证d.EnsureDone();d.FinishTransaction();// 最后阻止 defer 块中的回滚操作need_rollback = false;}
– END –
报告下载

大佬观点


