




👉导读
👉目录
Having said all this, there are, unfortunately, some people who have the return-code-mindset burned so deeply into their psyche that they just can’t seem to see any alternatives. If that is you, there is still hope: get a mentor. If you see it done right, you’ll probably get it. Style is sometimes caught, not just taught. 说了这么多,遗憾的是,有些人的思维模式中深深地烙印了返回错误码的思维,以至于他们似乎无法看到其他的选择。如果你就是这样的人,其实还是有那么一丁点希望的——找一个良师吧。如果你真能看到他正确的做法,你可能就会理解。有时候,追求风格真谛往往靠的是感悟,而非说教。
可能是某些 C++ 的大佬看到无休无止的错误码或异常难解难分发出的终极感慨——累了。
最近做了一些代码审阅的工作,也观察了一些审阅者们的评论,发现某些时候我们似乎真的错了。为了弄清楚这个问题,我决定做一个专栏来自始至终搞清楚这个问题的来龙去脉,并尝试探索出真正适合组织的选择方式。
01
1.1 异常 vs 错误
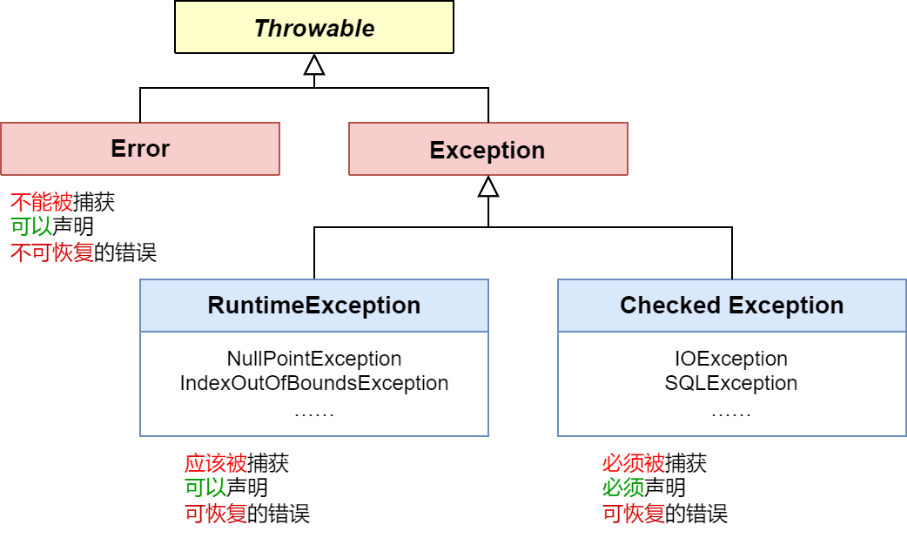
在正式开始研究之前,我们需要对一些专业的术语进行定义,最容易混淆的莫过于“错误(Error)”和“异常(Exception)”这两个词。我认为 Java 在这些名词的定义中做的比较明确。
The general meaning of exception is a deliberate act of omission while the meaning of error is an action that is inaccurate or incorrect。
通常来说,异常是程序中可以预料到的问题,而错误则是不准确或不正确而触发的行为。
上述的语言可能不能组成一个非常通俗易懂的场景。我们可依据两个简单的例子来说明这两个词的区别。
-
异常:这是程序中预料到的问题,就像你走路时可能会跌倒一样。这种情况是可以预见并处理的,例如你可以穿上防滑的鞋子,或者在地面湿滑时小心走路。在程序中,当遇到这样的问题时,你可以采取措施来“捕获”并处理这些异常,以使程序能够继续运行或以一种可控的方式失败。
-
错误:这是程序中出现的严重问题,就像你走在路上突然地面塌陷一样。这种情况通常是无法预见或处理的。在程序中,当遇到这样的问题时,通常表示存在一些更深层次的问题,这些问题可能需要修改代码或配置来解决,而不是仅仅通过异常处理机制来处理。
|
C# 中的错误 |
C# 中的异常 |
|
|
行为 |
因为缺少系统资源而引发的未意料到的表征 |
阻止程序正常流程的异常问题 |
|
发生的条件 |
缺少系统资源 |
程序正常运行中发生了一些问题(不满足的条件,或不准确的数据) |
|
可恢复性 |
不可恢复 |
可恢复 |
|
分类 |
Unchecked type |
Checked and unchecked exceptions |
|
示例 |
|
|
std::runtime_error 代表运行时错误,基类 std::logic_error 代表逻辑错误。由于某些需要前向兼容 C++11 之前的版本,所以会直接继承 std::exception。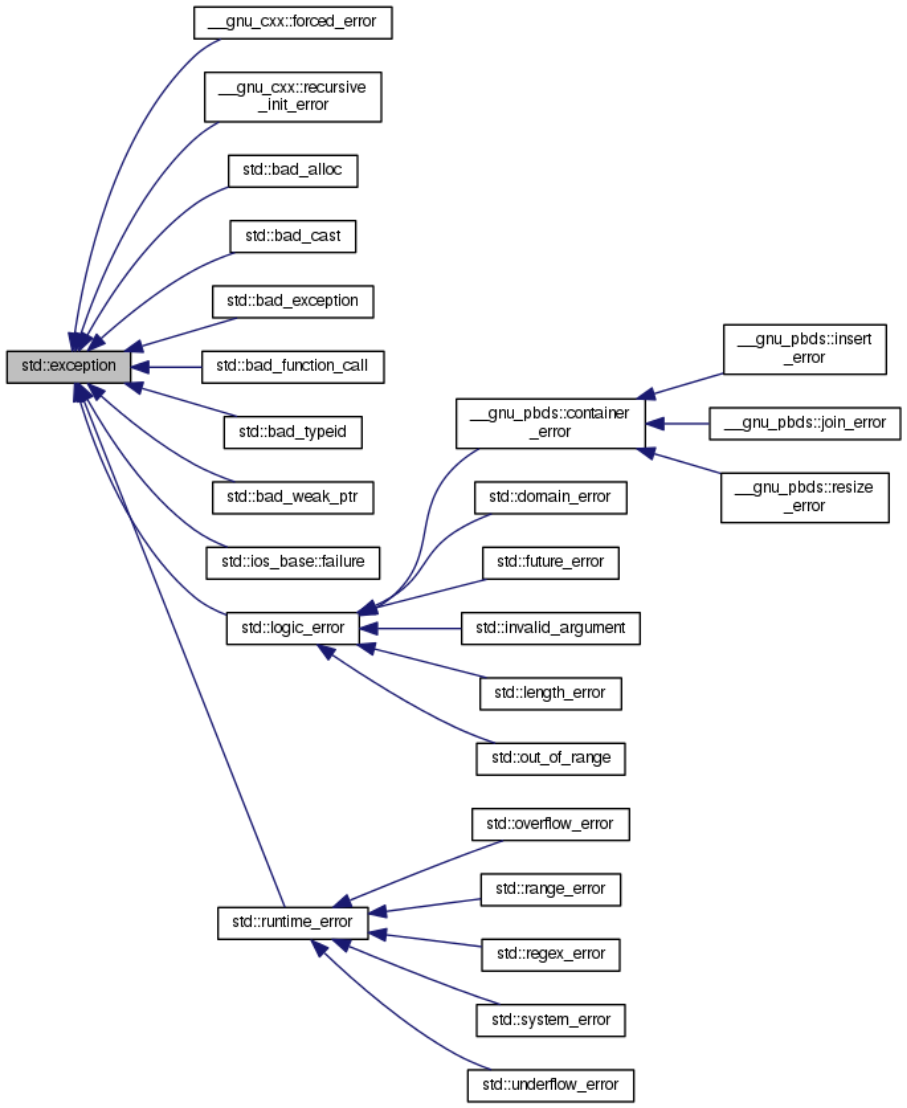
The C++ standard library provides classes to be used to report certain errors in C++ programs. In the error model reflected in these classes, errors are divided into two broad categories: logic errors and runtime errors. The distinguishing characteristic of logic errors is that they are due to errors in the internal logic of the program. In theory, they are preventable.
The class
logic_errordefines the type of objects thrown as exceptions to report errors presumably detectable before the program executes, such as violations of logical preconditions or class invariants.The class
runtime_errordefines the type of objects thrown as exceptions to report errors presumably detectable only when the program executes.
-
逻辑错误:抛出时用于报告程序执行之前就能够被检测到的错误,例如违反逻辑判断先决条件或类的不变性。例如检查参数不合法,在执行一个类的某些操作时报告不支持这样的操作,或违反当前对象的某种状态等; -
运行时错误:抛出时用于报告执行某些程序时无法被检测到错误,例如打开一个不存在的文件,这个文件存在与否和本身程序没有关系,只有在运行之后才能知道这个文件是否存在。收到一个非法的 JSON 数据包通常情况下也被认为是一个运行时错误。
注意上述逻辑错误和运行时错误是相对于面向对象的分析与设计而言的,对于一个有责任的业务开发,应该尽量避免自己的编写的程序中出现运行时错误——比如你对文件进行分析之前应该考虑到这个文件可能无法打开(文件不存在?没有权限?),然后在自己的程序中捕获这样的异常,并转换成逻辑错误——代表我这个程序不会因为一个运行时错误导致不能继续执行了,这个异常是在我设计之初就被考虑好的。
1.2 异常处理的发展历史
本文不太想讨论关于错误的处理方式,但对于异常处理(Exception Handling)的历史由来已久。
异常处理的概念可以追溯到 1951 年的 UNIVAC I 计算机,它是第一台拥有硬件异常处理功能的机器。软件的异常处理发展在 1960 年代和 1970 年代。LISP 1.5(1958-1961)允许通过ERROR伪函数引发异常,类似于由解释器或编译器引发的错误。异常被ERRORSET关键字捕获,如果出现错误,它会返回NIL,而不是终止程序或进入调试器。
PL/I 大约在 1964 年引入了自己的异常处理形式,允许通过 ON 单元处理中断。MacLisp 观察到 ERRSET 和 ERR 不仅用于错误引发,还用于非局部控制流,因此在 1972 年 6 月添加了两个新的关键字,CATCH 和 THROW。现在通常被称为 finally 的清理行为是在 1970 年代中后期的 NIL(New Implementation of LISP)中引入的,被称为 UNWIND-PROTECT 。这个概念随后被 Common Lisp 采用。与此同时,在此模式中中的 dynamic-wind 处理了在闭包中的异常。第一篇关于结构化异常处理的论文是 Goodenough 在 1975 年发布的。从 1980 年代开始,异常处理被许多编程语言广泛采用。
但现实情况是,目前对于一些广泛的底层的错误还是依然通过硬件中断来实现的。如大家非常常见的除 0,在触发中断之后,控制权通常会交给操作系统的中断处理程序。这个处理程序将决定如何处理这个中断。在某些情况下,操作系统可能会选择终止导致中断的程序,并且报告一个错误消息。在编译器级别,微软支持 SEH 作为一种编程技术。Visual C++ 编译器为此目的提供了三个非标准关键字:__try,__except 和 __finally。其他异常处理方面由一些 Win32API 函数支持,例如 RaiseException 可以手动触发 SEH 异常。Windows XP 引入了 Vectored Exception Handling(VEH)。VEH 提供给 Windows 程序员使用,如 C++ 和 Visual Basic。VEH 并未取代 SEH,而是与 SEH 并存,其中 VEH 处理器优先于 SEH 处理器。与 SEH 相比,VEH 更像是由内核传递的 Unix 信号。
GCC 的处理方式略有不同,但细节也和 Windows 结构化处理 异常也类似,但为了提供跨平台支持异常处理,使用了 libunwind 来用于异常的内部处理。异常处理过程需要构建和管理一种称为“异常表”的数据结构。当一个异常被抛出时,运行时系统会查看异常表来确定应该如何处理异常。特别是,在执行栈展开(unwinding)过程中,运行时系统需要知道每个函数调用帧如何保存和恢复寄存器状态。通过这种方式,它可以逐帧回溯,恢复到抛出异常之前的状态,然后跳转到合适的捕获块来处理异常。
1.3 小结
对于阅读本文章,首先需要了解一些预备知识。
-
错误和异常在本文中属于特定领域的专业术语,错误特指一些底层的无法恢复的问题,如内存不足、资源不够、内存越界等;而异常则表达式程序执行过程中的异常流。 -
早期,由于计算机、硬件、操作系统、编译器功能比较单一,使用了设置错误码,设置跳转的方案简单处理异常; -
由于时代的发展,操作系统(Windows + MSVC 或 Linux + GCC)都发展了一套基于操作系统和编译期联合实现的方式,来实现异常,这样在异常被抛出时就可以保留调用帧和寄存器状态,通过回溯恢复到抛出前的状态。
02
首先我们需要搜集出现在已经存在的所有的错误或异常的几种方式。
2.1 全局错误码
2.1.1 C 语言的最原始的实践 errno
errno 是一个在 C 语言和其他采用 C 标准库的语言(比如 C++和 Python)中用于报告错误状态的全局变量。这个名字来源于”error number”的缩写。当系统调用或库函数失败时,这个变量通常会被设置为一个特定的错误码,你可以检查这个错误码以确定失败的原因。errno 使用例子是尝试打开一个文件,如果文件不存在,fopen 函数会返回 NULL,并设置 errno 为 ENOENT(”No such file or directory”的错误码)。#include <stdio.h>#include <errno.h>int main() {FILE *file = fopen("nonexistent_file.txt", "r");if (file == NULL) {perror("Error opening file");printf("Error code: %dn", errno);} else {fclose(file);}return 0;}
fopen 尝试打开一个不存在的文件。当 fopen 返回 NULL 时,我们知道有错误发生,可以通过 perror 函数打印出错误消息。此外,我们还打印出 errno 的值以便进一步的调试。注意,errno 的值在成功的系统调用或库函数之后不会被清除,所以在检查 errno 之前,你需要确保之前有一个失败的系统调用或库函数。errno 变量的冲突,现代的操作系统和 C 库实现会为每个线程维护一个单独的 errno 值。这通常通过线程局部存储(Thread-Local Storage, TLS)来实现。errno 时,它不会影响到其他线程的 errno 值。所以 C 使用宏 errno 来定义局部线程的错误码,因此,只要你的系统和库支持线程局部存储(现代的 Unix-like 系统和 Windows 都支持),你就不需要担心在多线程环境中使用 errno 会有冲突的问题。libco 在切换协程时,只有在一些网络相关的操作中保存了 errno,但如果自己使用协程中的 co_yield_ct 切换协程,co_resume 恢复协程时,并没有把当前协程环境中的 errno 同步恢复到当前线程中。即当你手动调用协程切换之前,需要自行将 errno 保存到局部变量或协程变量中。另注意在开源版的 libco 中,没有找到任何对 errno 的特殊处理。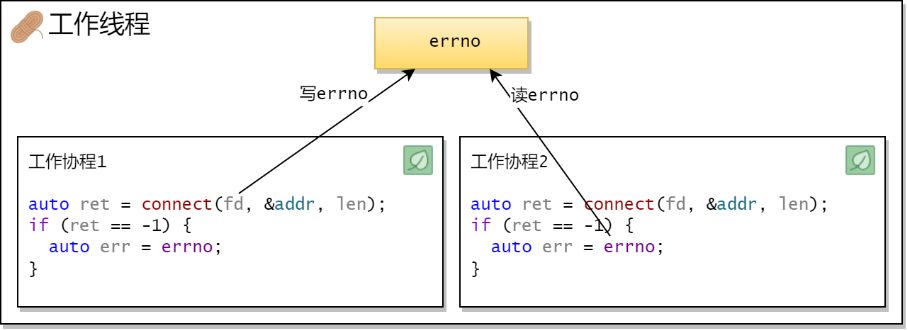
-
工作协程 1 调用 connect方法,由于connect会触发协程切换,很有可能connect在失败时写入了工作线程的errno -
如果此时切换工作协程 2,工作协程 2也是曾经返回 ret == -1 -
那么 工作协程 2 获取到的 errno将是由 工作协程 1connect错误写入的
-
将所有 Hook 住的函数都重写,把 errno保存到协程变量空间中,在切换协程之后立即恢复协程空间中的errno到当前工作线程。 -
将所有 Hook 住的函数,只有在明确了 errno不被修改时才做协程切换,否则就不做协程切换。
errno 的优劣很明显:| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 使用简单 | 只要是符合 POSIX 系统的都支持该方法 |
| ✔️ | 和函数实际返回值解耦 | 因为 C 语言函数通常会返回一个有意义的返回值例如 open 会返回一个 fd,opendir 返回一个指针。而 C 语言中大量使用空指针来表示返回结果失败。就算是没有返回值的函数,通常也会返回一个 int ,例如 connect 当失败时会返回 -1(早期 C 语言并不含有布尔类型,所以通常用 0 表示成功,-1 表示失败) |
| ⚠️ | errno 不能保证原子性 |
需要框架额外操作才能保证原子性,不过新的编译期已使用 errno 宏来作为实现,这样保证了线程中独立的副本,但如果使用其他协程框架,还需要进一步保证 |
| ❌ | 无法返回错误具体原因 | 虽然使用 strerror 可以获取具体错误信息的错误描述,但此方法只能简单的翻译错误码对应的信息,如果开发者需要加入自己的上下文或者调用的前后的描述信息,还需要额外的操作 |
| ❌ | 存在错误码限制 | 由于是内核所使用的错误码,所以这些错误码通常都会被只能记录在 errno -l 所列出的错误码中,这些错误码会将名称使用 #define 定义一个符号变量。 |
| ❌ | 确实上下文调用帧信息 | 对于级联调用如果出错了,需要一级一级的级联返回,这样对于大型的业务系统简直就是灾难,大多数第三方的开源库使用宏来级联传递返回值,想知道每一级调用还需要有特殊的技巧 |
| ❌ | 没有错误码单独契约定义 | 单从头文件中无法推测一个函数到底有多少错误码,所有的错误码都会被记录在操作手册或注释中。 |
2.1.2 OpenSSL 全局错误栈
对于一些复杂的库,上下文调用帧的信息是非常重要的场景信息。为了降低代码的耦合度,通常情况而下会把使用频率高的函数根据自己的职责拆分,这样每个函数可能都没有问题,一旦组合起来,就没办法为每种场景都分配一个唯一的错误码。此时就需要通过上下文调用帧来调试或发现问题的根源。
OpenSSL 是一个著名的 C 语言库,它是一个强大的安全套接字层密码库,包含了主要的加密、哈希和证书签名手段。它提供了丰富的应用程序用来保护数据的安全性。OpenSSL 不仅是一个加密库,它还提供了一套完整的应用程序接口用于处理 SSL/TLS 协议。
OpenSSL 提供了一系列的函数用于处理错误。当 OpenSSL 的一个函数调用失败时,它通常会将一个或多个错误代码压入错误堆栈。然后,你可以使用 OpenSSL 提供的错误处理函数来获取和处理这些错误。
下面是一些 OpenSSL 错误处理相关的函数:
-
ERR_get_error:从错误栈中弹出一个错误代码。 -
ERR_peek_error:查看错误栈顶部的错误代码,但不从堆栈中移除。 -
ERR_error_string_n:将错误代码转换为可读的字符串。
以下是一个使用这些函数的例子:
#include <openssl/err.h>#include <openssl/bio.h>#include <stdio.h>void inner_foo() {ERR_put_error(ERR_LIB_EVP, 0, ERR_R_PEM_LIB, __FILE__, __LINE__);ERR_add_error_data(1, "Data from inner");}void foo() {inner_foo();if (ERR_peek_error()) {ERR_put_error(ERR_LIB_EVP, 0, ERR_R_SYS_LIB, __FILE__, __LINE__);ERR_add_error_data(2, "Custom error data: ", "Data from outter");}}int main() {BIO *bio_err;bio_err = BIO_new_fp(stdout, BIO_NOCLOSE);foo();unsigned long err_code = ERR_peek_error();if (err_code) {ERR_print_errors(bio_err);}BIO_free(bio_err);return 0;}
最终将输出,每次添加错误的错误信息。
140334352819264:error:06000009:digital envelope routines:digital envelope routines:PEM lib:/app/example.cpp:6:Data from inner140334352819264:error:06000002:digital envelope routines:digital envelope routines:system lib:/app/example.cpp:13:Custom error data: Data from outter
同样的,OpenSSL 作为一个 C 语言的函数库在使用时有诸多限制,也是将错误码内含到单独的库中,并提供了可视化的错误输出函数。如果是使用 C++ 语言,那么编写代码就变得比较简单,因为可以将这个错误对象封装到一个类中,这个类是进程中单例的。每次通过语言化 API 来操作这个对象。
同时错误栈,还记录的发生异常的源代码位置和上下文,这使得嵌套调用中能够非常清晰的知道异常是怎么发生的。
让我们总结一下这样的一种方式的优缺点:
| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 调用帧记录 | 通过每次调用 ERR_put_error 可以把当前的上下文记录到异常信息中,但很显然不那么智能。 |
| ✔️ | 错误码集中管理 | 所有的错误码、甚至是库或场景都被记录在单独的文档和头文件中,方便使用方查询。 |
| ✔️ | 错误码限制 | 需要新增或修改错误码时,修改头文件和文档即可修改,和系统的错误码解耦。 |
| ✔️ | 解耦函数和返回值 | 由于错误错误栈被保存到一个全局区域,所以任何函数都不会在签名中体现出错误相关的参数或返回值,这样使得函数非常纯粹 |
| ❌ | 使用复杂 | OpenSSL 库说实在的用起来一点也不简单,也不直观。如果使用类似 std::stack<OpenSslError> 这样的 C++语法,可能使用起来更加简单,但并不妨碍我们对其思想的研究 |
| ❌ | 原子性 | 需要框架额外操作才能保证原子性,对于协程的其他库,需要在切换、恢复时同时恢复错误栈中的内容。遗憾的是,OpenSSL 并没有提供保存、恢复这样的 API,所以对于任何出现需要保存、回复错误栈时的场景都非常难以实现。 |
2.1.3 专用全局错误对象——VB/VBA
Visual Basic 或 Visual Basic for Application 中在 errno 的思想上将运行时错误扩展成一个全局对象 Err。Err 对象是个全局对象,具有默认错误码的属性。但和 errno 不同的是,当使用 Raise.Err 方法抛出一个运行时错误时,默认情况下会弹出一个对话框,此时如果是在 VB 虚拟机中运行,会弹出调试界面,此界面会显示当前当初抛出代码行数。
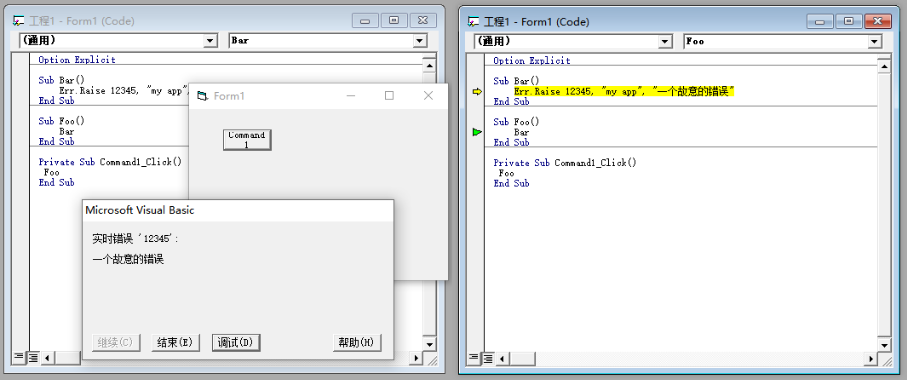
On Error 语句在运行时捕获和处理异常。-
On Error GoTo <行标>:如果捕获到了错误,直接跳转到标签之后的代码,有点类似于 C 语言中常用的if (cond) goto label;这样的写法。在行标后的语句处理完成后,还可以使用Resume语句进行错误恢复 -
Resume:重新执行错误的语句 -
Resume Next:执行下一句语句 -
On Error Resume Next:如果捕获了错误,直接运行下语句代码。 -
On Error Goto 0:如果捕获到了错误,放弃之前的语法,直接由 VB 虚拟机弹出错误对话框终止程序
Public Sub DoSomething()' 如果发生错误,就直接跳转到 ErrorHandler 标签进行处理On Error Goto ErrorHandlerErr.Raise -123, "DoSomething", "Error Handled by procedure Error Handler"' 恢复系统处理错误,直接时期弹出对话框并终止程序On Error Goto OErr.Raise -456, "DoSomething", "Error Handled by Client/Calling Procedure."Exit Sub' 这个标签用于处理错误ErrorHandler:MsgBox Err.descriptionResume Next '处理完成之后恢复到下一语句End Sub
| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 可视化调用帧记录 | 借助 IDE 的支持,可以在发生任意运行时异常,都定位到调用函数和代码 |
| ✔️ | 解耦函数和返回值 | 使用全局的 Err 对象来保存错误信息,所以函数和 Sub 都可以保持单一的职责 |
| ✔️ | 使用简单 | 直接使用 Err.Raise 就可以抛出运行时错误,On Error 语句简单明了 |
| ✔️ | 具备异常恢复和重试 | 少数具备语言层面直接执行下一句的能力,其他几乎只能使用 for 循环重试或 try..catch.. 忽略 |
| ⚠️ | 缺乏运行时工具 | 调用帧的一些信息只能在调试时展示,如果发布成 EXE,程序将直接终止运行 |
| ❌ | 错误码局限性 | 只支持 16 位的错误码,且 1~1024 为系统的保留的错误码,而且并没有一个规范定义需要将错误码单独定义在一个文件中 |
| ❌ | 缺乏并发的支持 | VB/VBA 比较早期的集成化开发环境,不具备多线程乃至协程的开发能力 |
2.2 返回值即错误
2.2.1 函数直接返回错误码
libcurl,这个非常广泛使用的 C 语言库单独定义了一个 CURLcode 的枚举,并非常详细的将所有库的枚举都定义在 curl.h 中。CURLcodeCURL *curl_easy_init(void);CURLcode curl_easy_setopt(CURL *curl, CURLoption option, ...);CURLcode curl_easy_perform(CURL *curl);void curl_easy_cleanup(CURL *curl);CURLcode curl_easy_recv(CURL *curl, void *buffer, size_t buflen, size_t *n);CURLcode curl_easy_send(CURL *curl, const void *buffer, size_t buflen, size_t *n);
libcurl 虽然是一个 C 语言库,但依然是使用了面向对象的开发模式。curl_easy_init curl_easy_cleanup 分别代表构造函数和析构函数,其他的都是成员函数。析构函数不会抛出异常,构造函数一定会返回一个 CURL* 表示成功或失败,其实也是代表了 RAII 的思想——即你不可能拥有一个非正常状态的 CURL 对象。libcurl 也提供了更加高级记录详细错误的用法,开发者可以使用 CURLOPT_ERRORBUFFER 这个选项来通知 libcurl 将详细的错误报告给一个字符串缓冲区,这个缓冲区是由开发者提供的,libcurl 不会对其进行生命周期的管理。#include <stdio.h>#include <curl/curl.h>int main() {CURL* curl;CURLcode res;char error_buffer[CURL_ERROR_SIZE]; // 用于调用方管理的错误信息缓冲区curl = curl_easy_init();if (curl) {curl_easy_setopt(curl, CURLOPT_URL, "http://www.qq.com");curl_easy_setopt(curl, CURLOPT_ERRORBUFFER, error_buffer); // 告诉 libcurl 将详细错误信息输出至此res = curl_easy_perform(curl);if (res != CURLE_OK) {printf("Error:%sn", error_buffer); // 输出详细的错刷信息}curl_easy_cleanup(curl);}return 0;}
然而某些团队对于每个函数都设置一个固定的枚举只感觉麻烦,而枚举值在 C 语言中可以直接向下转化为 int 类型。所以某些团队直接使用 int 类型作为所有的业务函数的返回值——此举动带来一些的争议。
作为 cpp 萌新想咨询几个最佳实践:
C++没有 defer 之类的机制, 保证一个函数无论是异常退出 还是 错误退出 都能清理资源的最佳实践是什么?
大量的判断和重复代码如何解决, 类似: 而且目前公司在推圈复杂度,这种代码怎么降低复杂度?
其实争议中问题最大的来源是这样的写的一些代码存在代码圈复杂度过高的问题。
但作为组织上——特别是对于一个超大规模的复杂系统而言——使用 int 作为单一返回码无法对于契约的使用方或调用方进行限制,这样对于 libcurl 的小团队的作品而言还相对可控,小团队可以将所有的错误通过枚举固化下来,正如 libcurl 中使用 CURLcode CURLMcode CURLSHcode CURLUcode 来表示多个对象的不同错误码。
| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 使用简单 | 对于接口提供方来源是简单了,直接返回一个 int ,有些人甚至用一些奇葩的做法——返回当前代码行数。 |
| ✔️ | 不存在原子性冲突问题 | 返回值就是返回码,很直接的就符合原子性的思路。 |
| ✔️ | 不局限错误码定义 | 错误码可以自行在自己的头文件中扩展。 |
| ⚠️ | 强制错误码单独契约定义 | 只能靠业务团队的约束,或自行使用枚举定义,或使用集中化的错误码,如果非要使用 -1 也没辙,所以某些系统没事儿报个“系统错误”或“网络错误”也是极其不负责任的做法。 |
| ❌ | 无法通过返回值就能表示实际的意图 | 所有函数的返回码都是 int 类型了,完全扭曲的函数的本意。如果使用面向对象的方法与设计简直就是灾难——因为你没办法通过 UML 的顺序图来真实反应目标函数的职责(难道所有的函数的职责都是为了获取一个返回码吗)。 |
| ❌ | 无法返回错误具体原因 | 因为返回码就只有一个数值,所以对于具体发生的原因无从谈起,libcurl 使用另外的机制保证传递错误原因。 |
| ❌ | 缺失上下文调用帧信息 | 无任何调用帧信息。 |
2.2.2 同时返回值和错误
-
过度工程:面向对象设计常常会导致过度工程,使得代码结构过于复杂,不易于理解和维护。 -
性能损失:面向对象编程的抽象性往往会导致一定的性能损失。特别是在那些需要高性能的场合,如游戏编程和嵌入式系统开发中,面向对象编程可能不是最优选择。 -
强调数据隐藏,可能限制灵活性:面向对象编程强调数据的封装和隐藏,这可能会在需要高度灵活性的情况下限制开发。 -
不适合所有问题:面向对象编程并不适合所有的问题。有些问题可能更适合使用过程式编程或函数式编程来解决。 -
对象之间的关系可能复杂:在面向对象编程中,对象之间的关系可能会变得很复杂,尤其是当系统涉及大量的类和对象时。 -
重用和继承的问题:虽然面向对象编程强调代码的重用,但在实践中,往往很难找到合适的类进行继承,或者子类可能会破坏父类的行为。
panic() recover() 来集中化处理错误,总是在函数返回值之后增加一个 error 作为错误处理的结果。package sampleimport ("log""os")func main() {// 此时通过返回码第二个参数来判断失败与否f, err := os.Open("filename.txt")if err != nil {log.Fatal(err)}// 立即定义一个延迟函数用于清理 fdefer func() {if err := f.Close(); err != nil {log.Fatal(err)}}()// 安全的使用 f 这个文件}
Open 和 Close 两个函数都会返回错误作为最后一个返回值。通过 defer 来执行 return 前的资源清理。但问题也很突出。-
如果一个业务中绝大多数都是流程,那么对于每个非关注点的异常都需要有一个 if err这样的语句,造成对一些本来可以集中处理的极小概率发生的异常淹没在大量的冗余的代码中; -
某些团队通过圈复杂度来度量好坏(PS:本人一直认为圈复杂度工具是软件工程领域一个非常过时且无用的工具),造成圈复杂过高,无法通过代码评审; -
每次增加一个圈复杂度对于某些团队必须要增加这个异常分支的单元测试以保证其异常分支行数的行代码覆盖,这样会造成某些开发就算知道这是可能风险依然不去做这样的判断,甚至在设计函数时就不返回 err直接panic(err)。
Result 和 Option 枚举类型来实现。use std::fs::File;use std::io::Read;use std::io::Error;fn read_file_contents(path: &str) -> Result<String, Error> {let mut file = File::open(path)?; // 使用 ? 运算符,如果出错就提前返回let mut contents = String::new();file.read_to_string(&mut contents)?; // 使用 ? 运算符,如果出错就提前返回Ok(contents) // 成功时,返回 Ok 包装的结果}fn main() {match read_file_contents("filename.txt") {Ok(contents) => println!("File contents: {}", contents),Err(error) => println!("Failed to read file: {}", error),}}
if error 这样的语法,取而代之是 ?运算符 这样的语法糖。加上 match 这样的关键字,让一些落后的代码度量工具也没办法正确度量过时的圈复杂度,让代码度量回归的真正人看得懂这样一种本质的特性上。| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 使用简单 | 由于摆脱了面向对象的分析与设计,使得传递错误码和信息变得随心所欲,由于新语言特性的加持,任何错误的对象都必须有上下文的说明文字使其变得有意义 |
| ✔️ | 原子性 | 由于没有使用全局变量,所以就算有协程切换、线程切换,也不存在错误对象被非预期中修改的问题 |
| ❌ | 无法做到统一的错误码管理 | 并没有统一的错误码管理,错误的抛出也没有约束固定的错误码,接口契约也没有强制要求 |
2.2.3 std::error_code (C++11)
std::error_code 是一个平台相关的错误代码。每个 std::error_code 对象都包含一个来自操作系统或其他底层接口的错误代码,以及一个指向 std::error_category 类型对象的指针,该对象对应于该接口。std::error_category 是特定错误类别类型的基类,例如 std::system_category、std::iostream_category 等。每个特定的类别类都定义了 error_code 到 error_condition 的映射,并且持有所有 error_condition 的解释性字符串。错误类别类的对象被视为单例,通过引用传递。std::error_category 的原因主要有两个:-
提供映射: std::error_category提供了一种机制,通过这种机制,开发者可以定义特定于平台或库的错误代码与可移植错误条件 (error_condition) 之间的映射。这使得错误处理可以在不同的上下文和平台之间保持一致性。 -
提供解释: std::error_category还保存了用于解释错误条件的字符串。这使得开发者可以获取到与错误相关的有用信息,帮助他们更好地理解和处理错误。
std::error_category 成为了处理和传递错误信息的重要工具。#include <filesystem>#include <fstream>#include <iostream>#include <system_error>// 为我们单独定义的错误码定义一个命名空间namespace wxpay::error_cdoe {// 这里定义个单独的枚举用于记录所有的错误码enum class WxPayErrorCode {kInvalidOpenTestFile = 0x1375212,kInvalidEmptyFile = 0x1375213,};// 这个类型是和错误码匹配的,用于将错误码翻译为可读的错误信息class WxPayErrorCategory : public std::error_category {public:static const WxPayErrorCategory& Instance() {static thread_local WxPayErrorCategory instance;return instance;}const char* name() const noexcept override { return "WxPayErrorCategory"; }// 用这个继承的函数用于翻译错误码std::string message(int ev) const override {switch (static_cast<WxPayErrorCode>(ev)) {case WxPayErrorCode::kInvalidOpenTestFile:return "Cannot open test file!";case WxPayErrorCode::kInvalidEmptyFile:return "Empty file!";default:return "Unknown";}}};// ADL 查找通用的将枚举错误码转换成 error_code 对象std::error_code make_error_code(WxPayErrorCode ec) {return {static_cast<int>(ec), WxPayErrorCategory::Instance()};}} // namespace wxpay::error_cdoe// 特化 is_error_code_enum 用于告诉 error_code 可被直接从枚举构造namespace std {template <>struct is_error_code_enum<::wxpay::error_cdoe::WxPayErrorCode> : true_type {};} // namespace stdstd::error_code OpenTestFile(std::filesystem::path filename, std::string& content) {std::ifstream file(filename.string());if (!file) {return wxpay::error_cdoe::WxPayErrorCode::kInvalidOpenTestFile;}std::string content_tmp((std::istreambuf_iterator<char>(file)), std::istreambuf_iterator<char>());if (content.empty()) {return wxpay::error_cdoe::WxPayErrorCode::kInvalidEmptyFile;}content = std::move(content_tmp);return {};}int main(int argc, const char* argv[]) {std::string content;auto r = OpenTestFile("test.txt", content);if (r) {std::cerr << "Failed to read file: " << r.message() << std::endl;return -1;}return 0;}
CURLcode 之类的第三方库,也可以非常好的移植到 C++ 语言中。2.2.4 absl::Status (Google Abseil)
absl::StatusOr<T> 类似于 C++17 的 std::optional<T> 或 Rust 的 Result<T, E>,但是它在错误的情况下提供了更多的上下文信息,通过 absl::Status 对象来表示错误状态,这个对象可以包含一个错误码和一个描述错误的消息。absl::StatusOr<T> 的简单示例:#include "absl/status/statusor.h"absl::StatusOr<std::string> ReadFile(const std::string& filename) {std::ifstream file(filename);if (!file) {return absl::NotFoundError("File not found");}std::string content((std::istreambuf_iterator<char>(file)), std::istreambuf_iterator<char>());if (content.empty()) {return absl::UnknownError("Failed to read file content");}return content;}int main() {auto statusOrContent = ReadFile("test.txt");if (!statusOrContent.ok()) {std::cerr << "Failed to read file: " << statusOrContent.status().ToString() << std::endl;return 1;}std::cout << "File content: " << *statusOrContent << std::endl;return 0;}
不过在 StatusOr 这个系统中没有实现错误码这样的逻辑,即如果我希望知道系统重所有完备的异常是不可能的。absl::Status 被广泛应用到 google 各种开源库重如 Protobuf LevelDB Abseil 中。如果业务系统要对系统中个各类异常做准实时的监控和上报,仅凭 absl::StatusCode 中的状态码是远远不够的。
2.2.5 std::expected (C++ 23)
std::expected 是一个可以包含两种状态的模板类:预期的值或错误。它类似于 std::optional,但在无法生成预期值时,它可以携带一个错误信息,而不是简单的空状态。这使得函数可以返回它们可能产生的值,或者在出现错误时返回一个错误对象。-
错误处理更明确:与使用异常不同,使用 std::expected时,错误路径是显式的,因此更易于理解和跟踪。 -
性能: std::expected可以用来避免抛出和捕获异常,这在某些情况下可能导致较大的性能开销。 -
可组合性: std::expected对象可以被链式组合,使得错误处理变得更简单。
-
需要显式处理错误:使用 std::expected需要检查并显式处理错误,这可能会增加代码复杂性。 -
接口复杂性:函数必须返回 std::expected,并且必须定义错误类型,这可能使接口变得更加复杂。
#include <expected>#include <filesystem>#include <fstream>#include <iostream>// 这里定义个单独的枚举用于记录所有的错误码enum class WxPayErrorCode {kInvalidOpenTestFile = 0x1375212,kInvalidEmptyFile = 0x1375213,};std::expected<std::string, WxPayErrorCode> OpenTestFile(std::filesystem::path filename) {std::ifstream file(filename.string());if (!file) {return std::unexpected(WxPayErrorCode::kInvalidOpenTestFile);}std::string content((std::istreambuf_iterator<char>(file)),std::istreambuf_iterator<char>());if (content.empty()) {return std::unexpected(WxPayErrorCode::kInvalidEmptyFile);}return content;}int main(int argc, const char* argv[]) {auto r = OpenTestFile("test.txt");if (!r) {std::cerr << "Failed to read file: " << static_cast<int>(r.error())<< std::endl;return -1;}auto content = std::move(*r);return 0;}
2.2.6 Boost.Outcome
errno 等)各自所带来的问题,这些问题有:-
异常处理:异常是 C++中默认的错误处理机制,它可以很好地描述函数间的”成功依赖”关系。然而,异常处理机制带来的开销和动态内存分配使得它不适用于实时或低延迟系统。另外,对于一些特殊的编程场景(例如需要在前一个操作失败后释放资源,或者当某个函数依赖于至少两个函数中的一个成功时),异常处理机制可能会变得很不方便。 -
errno:这种方法在函数失败时返回一个特殊值,并将错误代码存储在一个全局(或线程局部)对象 errno中。但是,这种方法的缺点是它会产生副作用,阻止了许多有用的编译器优化。另外,我们总是需要一个特殊的值来表示错误,这有时候会很麻烦。 -
错误码:这种方法将信息存储为 int类型,并通过值返回,从而使得函数保持纯净(无副作用和引用透明)。但是,所有可能的错误代码必须适应一个int并且不能与任何其他错误代码值重叠,这在扩展性上存在问题。 -
std::error_code:这是一个设计用来小而平凡的错误代码类型,可以表示世界上任何库/子系统的任何错误情况而不会发生冲突。其表示形式大致为:一个指向代表特定库,领域的全局对象的指针,以及一个表示该领域内特定错误情况的数值。
#include <boost/outcome/result.hpp>#include <boost/outcome/try.hpp>#include <filesystem>#include <fstream>#include <iostream>// 为我们单独定义的错误码定义一个命名空间namespace wxpay::error_cdoe {// 这里定义个单独的枚举用于记录所有的错误码enum class WxPayErrorCode {kInvalidOpenTestFile = 0x1375212,kInvalidEmptyFile = 0x1375213,kInvalidTooBig = 0x1375214,};// 这个类型是和错误码匹配的,用于将错误码翻译为可读的错误信息class WxPayErrorCategory : public std::error_category {public:static const WxPayErrorCategory& Instance() {static thread_local WxPayErrorCategory instance;return instance;}const char* name() const noexcept override { return "WxPayErrorCategory"; }// 用这个继承的函数用于翻译错误码std::string message(int ev) const override {switch (static_cast<WxPayErrorCode>(ev)) {case WxPayErrorCode::kInvalidOpenTestFile:return "Cannot open test file!";case WxPayErrorCode::kInvalidEmptyFile:return "Empty file!";case WxPayErrorCode::kInvalidTooBig:return "Too big file!";default:return "Unknown";}}};// ADL 查找通用的将枚举错误码转换成 error_code 对象std::error_code make_error_code(WxPayErrorCode ec) {return {static_cast<int>(ec), WxPayErrorCategory::Instance()};}} // namespace wxpay::error_cdoe// 特化 is_error_code_enum 用于告诉 error_code 可被直接从枚举构造namespace std {template <>struct is_error_code_enum<::wxpay::error_cdoe::WxPayErrorCode> : true_type {};} // namespace std// 如果文件是空就返回错误boost::outcome_v2::result<std::string> AnalysisFilieContent(std::string&& content) {if (content.empty()) {return wxpay::error_cdoe::WxPayErrorCode::kInvalidEmptyFile;}return std::move(content);}// 打开文件并读取内容boost::outcome_v2::result<std::string> OpenTestFile(std::filesystem::path filename) {std::ifstream file(filename.string());if (!file) {return wxpay::error_cdoe::WxPayErrorCode::kInvalidOpenTestFile;}std::string content((std::istreambuf_iterator<char>(file)),std::istreambuf_iterator<char>());// 这里使用一个宏来消除复杂度,如果上层函数返回失败,那么这个宏也会返回失败BOOST_OUTCOME_TRY(auto str, AnalysisFilieContent(std::move(content)));// 接下来判断if (str.length() > 10000) {return wxpay::error_cdoe::WxPayErrorCode::kInvalidTooBig;}return std::move(str);}int main(int argc, const char* argv[]) {auto r = OpenTestFile("test.txt");if (!r) {std::cerr << "Failed to read file: " << r.error() << std::endl;return -1;}auto content = std::move(r.value());return 0;}
比起使用 std::expected Outcome 使用了宏来代替级联的失败,这样而由于所有的 result 构造函数都采用了 [[nodiscard]] 关键字,所以你不能忽略带有 result 返回值的函数,否则会引发一个编译错误。
同时 boost::outcome_v2::outcome 还支持对异常的捕获。
2.3 参数中控制信息传递返回码
errno 中存在全局变量可能出现的冲突问题,有很多在设计 API 时,都将错误信息防止在参数中,这样就避免了全局函数冲突的问题。但这样做的结果还是会因为函数参数造成函数职责不纯粹。2.3.1 来自 std::filesystem (C++17) 的思考
std::error_code 的功能。例如:bool exists(const std::filesystem::path& p);bool exists(const std::filesystem::path& p, std::error_code& ec) noexcept;
std::error_code& 作为错误专用的搜集参数通过引用方式传入。使用哪个版本取决于你的错误处理策略。如果你希望通过异常来处理错误,那么可以使用第一个版本。如果你希望避免异常,并自己处理错误,那么可以使用第二个版本,并检查传入的 std::error_code 对象以获取错误信息。| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 将选择权交给使用者 | 使用者可以选择异常版本和非异常版本 |
| ❌ | 库的编写方式用起来很麻烦 | 每次都要写两个版本的函数重载 |
| ❌ | 调试信息缺失 | 单一的 std::error_code 并不能在使用时提供上下文相关的错误文本 |
2.3.2 google::protobuf::RpcController (Google Protobufs)
RpcController。RpcController 可以用来管理 RPC 的状态和控制。RpcController 有几个主要的方法,其中关于错误处理相关的有:-
Failed():如果 RPC 调用失败,这个方法会返回 true。 -
ErrorText():如果 RPC 调用失败,这个方法会返回一个描述错误的字符串。 -
SetFailed(const string &reason):这个方法可以用来设置错误状态和错误信息。
RpcController 中自定义错误信息,可以通过 SetFailed 方法。你可以传入一个字符串,来描述错误的原因。例如:controller->SetFailed("The method failed because of ...");Failed 方法和 ErrorText 方法,来获取错误状态和错误信息。例如:if (controller->Failed()) {std::cout << "RPC failed: " << controller->ErrorText() << std::endl;}
Failed 方法和 ErrorText 方法,来获取错误状态和错误信息。例如:| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 使用灵活 | 非常灵活的报告错误,并直接通过 SetFailed 来设置错误状态 |
| ❌ | 无错误码 | 没有集中的统一的错误码的管控,导致仅只有错误文本,对于大型的系统没有办法对各种错误码进行运营分析 |
| ❌ | 需二次加工 | RpcController 是纯虚函数的类,所以自己的系统中必须实现这个子类。目前 UCLI (Xwi 抽出的通用函数调用组件) 实现时增加了控制码、错误码、调用帧指针等错误信息 |
2.3.3 专用的错误搜集器
-
在构造函数中传入专门的 ErrorCollector 对象的引用,如果不传就使用默认错误收集器; -
成员函数调用过程中,返回一个失效的对象(如空指针),表示操作失败,并通过错误收集器来输出具体的错误; -
接入方可以继承错误收集器的基类,在每次调用成员函数后,判断返回结果是不是失效的,如果发生了异常,就从错误收集器中获取更详细的异常内容。
google::protobuf::compiler::Importer 来加载一个文件,并返回其语法分析结果。但如果遇到源代码不正确,如词法错误、语法解析错误,那么还需要传入一个 google::protobuf::compiler::MultiFileErrorCollector 的子类来对异常进行类似回调方式的处理。#include <iostream>#include <google/protobuf/descriptor.h>#include <google/protobuf/dynamic_message.h>#include <google/protobuf/compiler/importer.h>using namespace google::protobuf;using namespace google::protobuf::compiler;using namespace std;// 定义一个 MultiFileErrorCollector 的子类来处理错误class ErrorCollector : public MultiFileErrorCollector {public:void AddError(const string& filename,int line, int column,const string& message) override {cerr << "Error in file: " << filename << " at " << line << ":" << column;cerr << " => " << message << endl;}};// 在主函数中使用这继承好的错误搜集器来对异常进行处理int main() {DiskSourceTree st;sourceTree.MapPath("", ".");ErrorCollector ec;Importer importer(&st, &ec);// 动态从磁盘中加载 addressbook.proto 源文件const FileDescriptor* fileDescriptor = importer.Import("addressbook.proto");if (fileDescriptor == nullptr) {cerr << "Error: Could not import file." << endl;return 1;}// 创建动态消息工厂,这个工厂存储了动态消息的对象池,析构之后动态创建的消息将不再有效DynamicMessageFactory factory;// 查找具体的某个类型const Descriptor* descriptor = importer.pool()->FindMessageTypeByName("tutorial.Person");if (descriptor == nullptr) {cerr << "Error: Could not find message." << endl;return 1;}// 通过工厂动态创建出消息unique_ptr<Message> person(factory.GetPrototype(descriptor)->New());// 可通过反射接口来设置 person 中的字段return 0;}
std::optional<T> 来控制函数返回值的正确性。但就算是 Protobuf 对这样的实现也不那么优雅:-
纵览整个 Protobuf 库,里面大大小小的错误收集器就有好几个: -
io::ErrorCollector用于报告词法分析源文件时,由于分词导致的词法分析错误; -
DescriptorPool::ErrorCollector用于搜集语法分析器的错误,报告源代码中分词之后造成的语法冲突错误; -
compiler::MultiFileErrorCollector用于搜集编译期产生多个语法文件造成的编译错误,即将词法分析、语法分析的错误转发; -
各个类型使用搜集器的方法不一致: -
compiler::Importer使用构造函数传入compiler::MultiFileErrorCollector; -
compiler::ParserTextFormat::Parser通过void RecordErrorsTo(io::ErrorCollector*)传入; -
io::Tokenizer使用构造函数传入io::ErrorCollector; -
compiler::SourceTreeDescriptorDatabase为了支持源代码错误信息的报告,特地void RecordErrorsTo(MultiFileErrorCollector*)来复用DescriptorPool中的错误搜集器 -
接入方想找一个地方就是简简单单的输出一下错误,就要为不同场景做多种错误搜集器的适配。
| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 兼容性好 | 支持 C++11 之前陈旧的语法 |
| ❌ | 无集中控制 | 每种场景都需要继承一个专用的基类用于适配不同类型的错误搜集程序 |
| ❌ | 代码编写复杂 | 每次都需要判断函数返回值的合法性,代码复杂度高 |
2.4 对面向对象的分析与设计中异常控制的支持
2.4.1 语言层面的异常支持
-
C++:关键字 thrownoexcepttry...catch...异常对象std::exception及其子类; -
JavaScript:关键字 throwtry...catch...finally...,异常对象Error; -
Java:关键字 throwtry...catch...,异常对象Exception极其大量的子类,运用相当相当广泛; -
C#:关键字 throwtry...catch...finally,异常对象Exception以及子类,甚至在 MDSN 文档中都推荐使用异常而非错误码来控制流程; -
Delphi:关键字 raise..at..try...except...else...finally...end;,异常对象Exception及其子类。
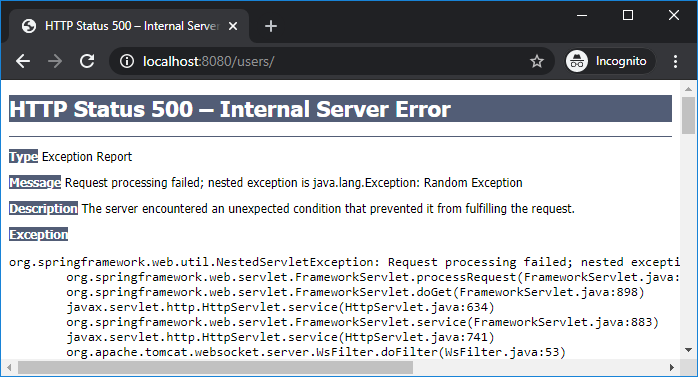
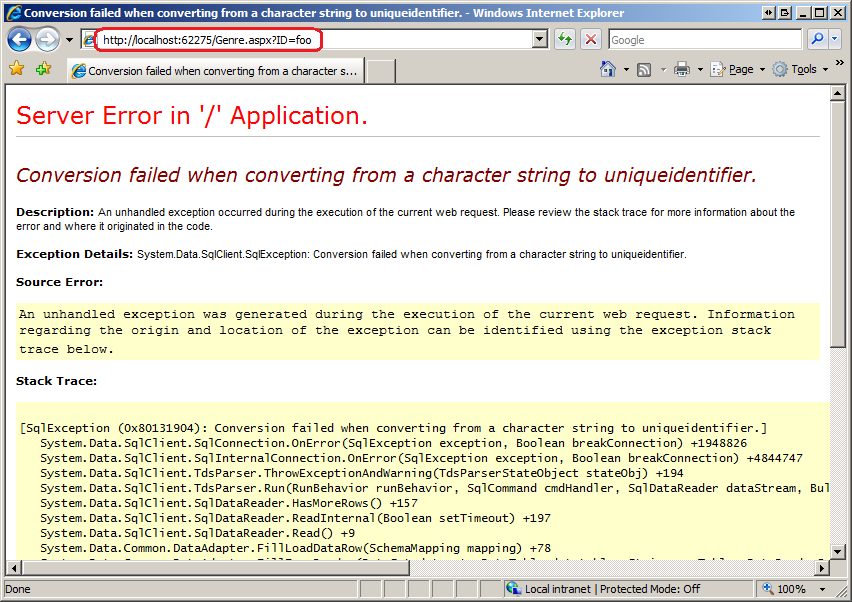
-
使用断言来检查永远不应发生的错误。使用异常来检查可能发生的错误,例如公共函数参数的输入验证错误。有关详细信息,请参阅异常与断言部分。 -
当处理错误的代码与通过一个或多个中间函数调用检测错误的代码分离时,请使用异常。当处理错误的代码与检测错误的代码紧密耦合时,请考虑是否在性能关键型循环中使用错误码。 -
对于每个可能引发或传播异常的函数,请提供三项异常保证之一:强保证、基本保证或 nothrow ( noexcept) 保证。 -
通过值引发异常,通过引用捕获异常。不要捕捉到你无法处理的内容。 -
不要使用 C++11 中已弃用的异常规范。有关详细信息,请参阅异常规范和 noexcept部分。 -
使用适用的标准库异常类型。从 std::exception类层次结构派生自定义的异常类型。 -
不要允许异常从析构函数或内存解除分配函数中逃逸。
| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 解耦函数和异常 | 这些语言当出现运行时异常时,都不会需要函数或对象成员额外添加存储空间来记录异常的上下文,错误码等信息。 |
| ✔️ | 不存在原子性冲突问题 | 当抛出异常时,语言层面会保证捕获住的异常就是抛出的位置,并逐帧的清理栈中的对象,所以就算是在多线程中,或任何协程库中,都不存在抛出的异常和捕获的异常不一致的问题。 |
| ⚠️ | 完整的调用帧 | 目前只有 C++ 还没有在语言层面上支持在抛出异常上记录调用帧信息,但可以规范一个自定义异常,在异常构造时保存 stacktract 信息。其他更高级专用的语言已经在各自的基类对象中保存了调用帧信息,好在 C++23 已经将获取调用帧的信息加入到标准库中了。 |
| ⚠️ | 失效路径执行效率不可预测 | 对于 C++ 而言,某些实时系统或许需要同等的执行效率,但对于悲观路径,如果嵌套层数过多,那么悲观路径效率将会很低。不过对于面对象对象设计的业务系统而言,此处并不是重点要考虑的,因为大多数情况下,面向对象的程序设计绝大多数都是乐观路径,乐观路径的执行效率要远大于悲观路径。而且比对动机数毫秒的网络请求,和大量的数据拷贝,这点执行效率几乎可以忽略不计。 |
| ❌ | 匹配错误码系统 | 这些高级语言采用面向对象的方法设计,认为所有的异常都是一种对象,错误码只是某些异常或某类异常的一种属性,而且既然都可以用类来区分错误了,为什么还要用孱弱的错误码来映射某一类型的异常呢? |
2.4.2 操作系统的支持
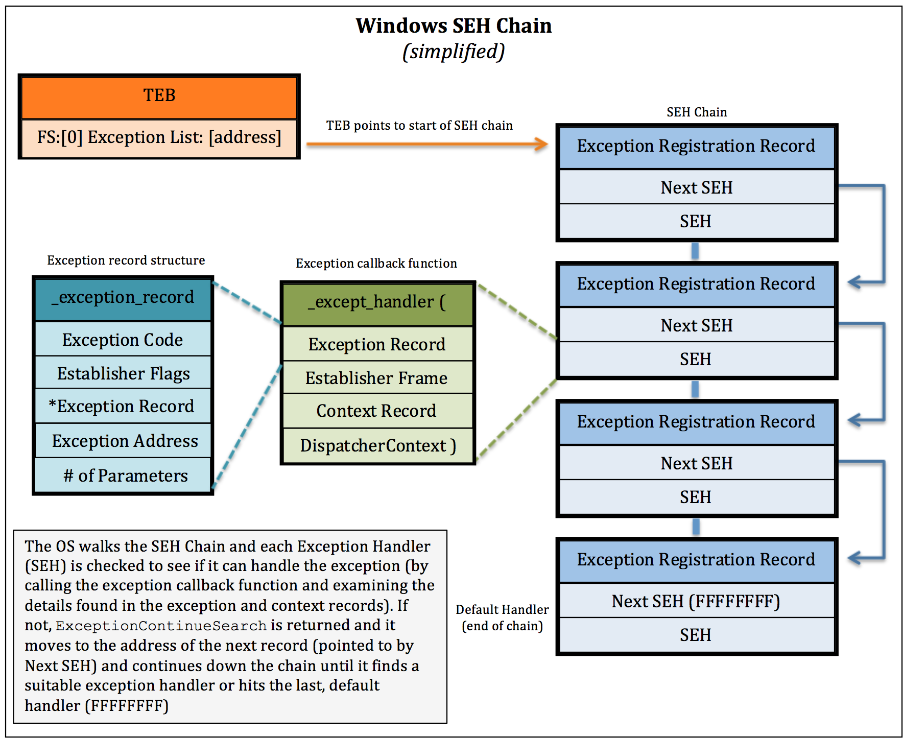
UNWIND_INFO)。这意味着编译器无需生成额外的代码来手动执行堆栈展开,并适当地调用异常处理程序。它只需要以堆栈帧布局和指定异常处理程序的形式发出展开表信息。-
集中处理异常:结构化异常处理允许你在一个地方集中处理在程序的多个地方可能发生的异常。这使得你可以更好地组织代码,并提供一种统一的方法来处理各种类型的错误。 -
更强的错误处理能力:结构化异常处理不仅可以处理来自程序代码的异常,还可以处理由操作系统或硬件引发的异常,例如访问违规、整数除以零、浮点溢出等。这种能力可以帮助你编写更健壮的代码,能够在遇到这些问题时不会崩溃。 -
可嵌套的异常处理:结构化异常处理允许在代码中创建多个异常处理程序,它们可以被嵌套在一起。这意味着你可以为特定的代码块指定特定的异常处理程序,如果该代码块没有处理某个异常,那么外层的异常处理程序可以捕获和处理该异常。 -
异常过滤:结构化异常处理提供了异常过滤的功能,允许你根据异常的类型或者其他条件来决定是否处理该异常,或者如何处理该异常。这为异常处理提供了更大的灵活性。 -
结构化的编程模型:结构化异常处理的设计与 C++ 的异常处理类似,使用 try/catch/finally块来标识可能引发异常的代码区域,以及处理这些异常的代码。这种结构化的编程模型使得代码更易于理解和维护。 -
兼容性:结构化异常处理与 Windows 的其他组件(如 COM 和 .NET)的异常处理模型相兼容,可以无缝地在这些环境中使用。
AddVectoredContinueHandler 函数。要移除此处理器,可以使用 RemoveVectoredContinueHandler 函数。同样,要添加向量异常处理器,可以使用 AddVectoredExceptionHandler 函数。要移除此处理器,可以使用 RemoveVectoredExceptionHandler 函数。| 优劣 | 描述 | |
|---|---|---|
| ✔️ | 解耦函数和异常 | 操作系统层面增加 Win32API 使得无论什么语言都可以非常灵活的使用 try..catch..finally 这样的语法来统一实现异常控制。 |
| ✔️ | 解耦编程语言和操作系统 | 任何语言包括不支持异常的 C 语言都可以使用 Win32API 来实现自己的异常处理功能。 |
| ✔️ | 不存在原子性冲突问题 | 操作系统保证在 Raise 和 Catch 之间的异常信息的原子性,不会被其他线程或协程中断。 |
| ✔️ | 完整的调用帧 | UNWIND_INFO 在操作系统层面保留了调用帧的基础信息。 |
| ✔️ | 额外的拦截能力 | 通过 VEH 中的函数可以实现在调用帧的任何地方发起异常时就可拦截异常的发生,这一点是传统的语言 try...catch...fainally 所不具备的。 |
| ❌ | 匹配错误码系统 | 操作系统级别的异常处理实际上已经弱化了错误码在区分异常时的角色,如果应用程序需要用到统一的集中式管理错误码,还需要自行设置。 |
2.5 小结
– END –
重磅活动

报告下载

大佬观点


