





本文介绍了大语言模型在低代码平台中的应用实践。首先从直观角度解释了大模型的基本原理,包括输入输出的过程以及选词策略。然后介绍了大模型在应用落地中的几种方案,包括文档问答、生成数据模型和生成页面。对于文档问答,通过向量搜索和生成器的方式实现,可以根据用户问题查找相关文档并生成回答。生成数据模型可以通过指令微调的方式,根据用户需求自动生成表结构定义。生成页面则可以通过微调模型,根据用户描述生成页面配置。文章还提到了大模型应用中存在的问题,如幻觉问题、窗口大小限制等。最后,介绍了评估大模型效果的方法和继续预训练的重要性。
简介
本文将介绍大语言模型在爱速搭低代码平台中的落地实践,包含以下内容:
-
大模型的直观介绍 -
大模型应用落地的几种方案 -
文档问答 -
生成数据模型 -
生成页面 -
自然语言查询数据 -
生成代码 -
对平台进行操作 -
大模型应用落地存在的问题
01
直观理解大模型

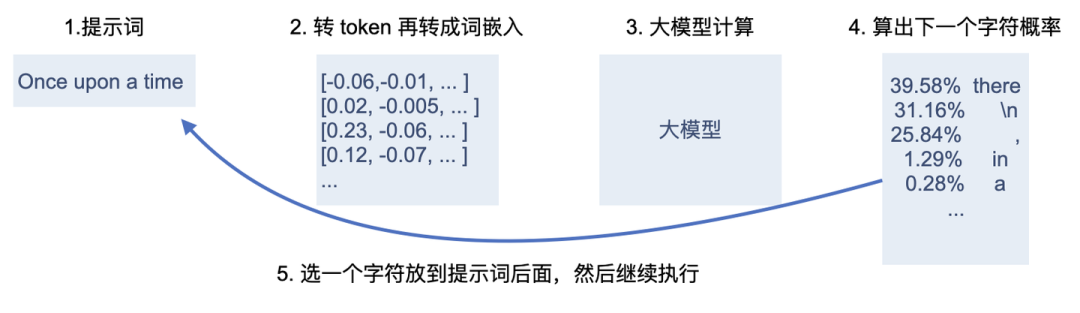
如果你能访问 OpenAI 的 Playground,它有个显示输出概率功能,可以查看输出时有哪些后续词及概率。
OpenAI 里显示输出概率
这里展开介绍其中一些应用需要关注的两个重要细节:token 和选词。
先来看 token,一句话输入到大模型后会先拆分成 token,以 ChatGPT 为例,它的词表可以从这里下载,一共有 100256 个不同符号,这个符号并不是单词或字母,而是 BPE 格式,其中有字母、特殊字符及 UTF-8 字节,比如下面是其一小部分,可以看到既有完整单词也有部分字符:
/gif
(Handle
anunci
/py
invalidate
MEP
tems
;]/
b'xe8x83'
运
taco
ADV因为 token 里有些不常用的汉字拆分成了字节,所以汉字对应的 token 会更多,具体可以使用 Tiktokenizer 工具查看,比如「艰难苦恨繁霜鬓」用了 16 个 token,其中的「繁」和「鬓」都占了 3 个 token。
很多国外的开源大模型数据集里中文较少,由于出现概率不高,导致不太常用的汉字就被拆分为了 UTF-8 字节,而由于大模型是一个个 token 输出,有可能在随机选择时选了错误的 UTF-8 字节导致输出乱码,另一方面如果领域很专业,有大量专有名词,在通用模型里往往会被拆分成不同的汉字,也使得输出时可能选错,因此在专业领域使用大模型时可能需要扩充词表,但扩词表必须有大量数据做继续预训练,只适合文本量很大的领域。
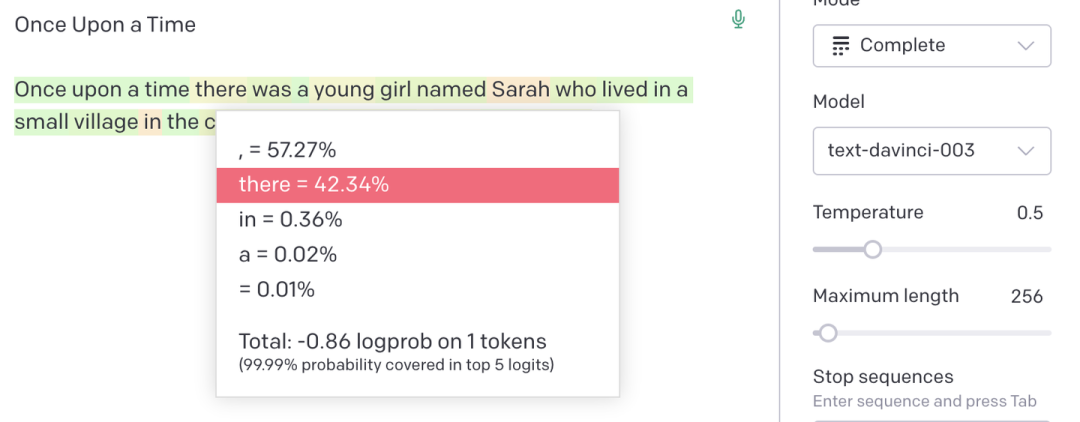
一个有趣的应用是我们可以根据 token 值的大小来判断某个单词流行程度,比如下图所示,图中左侧是输入文本,右侧通过不同颜色显示文本被拆分成了不同 token,右下角是每个 token 的索引 id
 使用 Tiktokenizer 查看句子被拆分成了哪些 token 及它们的索引
使用 Tiktokenizer 查看句子被拆分成了哪些 token 及它们的索引
可以看 JavaScript 比 TypeScript 更常见,因为对应的 token 索引 id 都更小,这是符合预期的,尤其是 TypeScript 还被拆分成了两个 token,只有在前面加个空格才能分配到一个带空格的完整 token,说明 TypeScript 在文本段落中间出现的概率高于开头。
据说 Reddit 有个用户整天灌水,出现比较频繁,所以他的 id 拥有了一个自己的专属 token
转成 token 之后,下一步是查询这些 token 对应的 embedding 向量,因为最终是要进行各种数学计算的,因此需要转成某种数学的表现形式,embedding 就是一种用向量来代表某个 token 的数学形式。
token 其实还包括了一些空白字符,因此在边界容易出问题,这是在应用时需要注意的。
以前面「Once upon a time」的例子说明,”Once”(后面有空格)的 token id 是 [7454, 220],其中空格的 id 是 220,但如果是 “Once upon”,token id 就是 [7454, 2402],其中 “upon”(前面有空格) 的 id 是 2402,而 “upon” 这个不加前面空格的单词 token 是 27287,前面提到过 id 值大意味着概率低,在大模型眼里,提示词结尾加不加空格是完全不同,加了就是用 [7454, 220] 预测 27287,不加就是用 [7454] 预测 2402,第一种是概率更低更难的,因此在写提示词的时候结尾不要加空格。
看完了 token,接下来介绍选词,前面提到大模型最终输出结果是每个 token 的概率,要选择哪个 token 作为下一个词呢?最简单的想法是选择概率最大的,但这样并不好,一方面是单次概率最大不代表全局最优,另一方面导致大模型同一个问题每次输出结果都一样,对于创意类的场景不合适。因此目前的做法是根据输出概率来做采样,概率高的 token 更容易输出。
在实际应用的时候,大模型通常会有个可调整的参数叫 Temperature,它可以控制大模型输出结果更稳定还是更多样,它是怎么实现的呢?这里用代码来解释一下,比如我们假设大模型输出了这个向量
output = torch.FloatTensor([0.1, 0.2, 0.3, 0.4, 0.5])通过 softmax 函数我们可以将输出结果转成总和为 1 的小数,每个小数就是输出概率,这就是大模型最后算出的结果
torch.nn.functional.softmax(output, -1)
# 输出为 [0.1621, 0.1792, 0.1980, 0.2188, 0.2419]
比如第五个值被选中的概率是 24.19%,这里每个数组的索引就是前面提到的 token id,第五个值代表 token id 为 5。
如果我们将输出结果除以 0.1,结果就变成如下:
temperature = 0.1
torch.nn.functional.softmax(output / temperature, -1)
# 输出为 [0.0117, 0.0317, 0.0861, 0.2341, 0.6364]
这时第五个值的概率变成 63.64% 了,被选中的概率大幅增加,输出结果更为稳定
而如果是除以 2,就变成:
temperature = 2
torch.nn.functional.softmax(output / temperature, -1)
# 输出为 [0.1805, 0.1898, 0.1995, 0.2097, 0.2205]
这时各个列的输出概率就被压平了,第五个值的的概率变成 22%,而之前第一个值的概率从 1% 变成了 18.05%,比之前更有可能被选中了,这就使得大模型输出结果更多样,也意味着跟容易瞎说。
因此将 temperature 值设小一点模型就能很稳定输出,另外 temperature 是被除数,所以不可以为 0,有些平台支持 0 是做了特殊处理,比如可以转成 top_k 为 1。
不过改成 0 也不能完全保证结果唯一,根据 OpenAI 员工 boris 的说法,GPU 浮点数计算的时候有不确定性,而且多个 GPU 推理时 a*b*c 可能被计算为 (a*b)*c 或 a*(b*c),这两个结果可能会微小不同,导致最终结果不唯一。
前面花了很多篇幅介绍 token 及选词策略,因为这是在大模型应用时控制输出的重要机制,在不改变大模型参数的情况下,我们可以:
-
提升推理速度,比如 Speculative Sampling,它的原理是用个小模型来生成一段,再让大模型来挑选是否可用,这个方式能提升 2-3 倍推理速度。 -
优化推理效果,比如使用 Beam search 来搜索更好的结果,它通过多次搜索来找到更优结果,但会牺牲性能,因此实际应用中比较少见。 -
控制输出格式,在应用中我们通常需要大模型输出 JSON 格式,而大模型有时候会幻觉导致输出错误,这时可以在解码时进行干预,比如发现新 token 会导致 JSON 语法错误就自动修正,比起全部输出后再修正效果更好。
02
大模型应用落地的几种方案
了解了大模型基本原理,接下来我们看如何在产品中应用。
在实际应用前我们需要了解大模型适合做什么,以及有哪些对接方案,根据最新的一篇评估综述,大模型(主要是指 ChatGPT)在各个任务上的表现是:
-
做得好的 -
情感分析(Sentiment analysis) -
文本分类(Text classification) -
对话(Dialogue) -
翻译(Translation),对于 ChatGPT 来说尤其擅长翻译到英文 -
问答(Question answering) -
写作(Writing tasks) -
做得不好的 -
语义理解(Semantic understanding),还不如 BERT -
推理(Reasoning),这个细分领域较多,在数学、符号、常识、空间等方面的推理都比较差,但在时间、医学方面的推理表现尚可 -
摘要(Summarization),有时候还会生成比内容更长的摘要
-
能容忍错误,没有唯一正确答案,比如起名、续写文章等 -
结果容易验证,比如给开发者用的代码补全,开发者知道自己想要什么
-
问答,解答用户问题,比如教育、医疗、法律类问题,客服场景等,这是目前很常见的应用。 -
聊天,主要是情感陪伴类场景,游戏 NPC 交互等,现有大模型原生应用第二火的 Chracter 就是这种。 -
文本转换(广义翻译),我把这种模式叫广义翻译,它的表现是将用户语言转成另一种语言,比如自然语言转 SQL、转代码、转命令,可以认为摘要也是一种翻译。 -
续写,主要用在文章和代码场景中,帮助续写内容。 -
填空,调用某个外部工具,比如订机票场景,需要填的内容包括起点、终点、时间,根据用户语言抽取这些内容,如果不满足就一直问,用于功能固定的场景,之前火过一段时间的智能助理大多是这样实现的。 -
组合工具完成任务,针对某个复杂问题,大模型需要组合多种工具来完成任务,需要一定的推理能力。
了解了前面的基础知识后,接下来开始详细介绍爱速搭中对大模型的应用。
03
文档问答

文档问答是目前大模型最常见的应用,因此爱速搭在 amis 文档中也尝试了基于大模型的文档问答。
它的基本原理是根据用户输入查找相关文档段落,然后让大模型回答,比如大模型的提示词是
请根据上下文内容回答问题,如果无法回答,回答“找不到相关答案”:
上下文是:
{content}
问题是:{question}
回答:其中 {question} 是用户问题,而 {content} 是检索到的相关文档段落内容,比如下面实际运行时的例子
请根据上下文内容回答问题,如果无法回答,回答“找不到相关答案”:
上下文是:
### CRUD 顶部有重叠遮挡
在初始化 amis 渲染器的时候设置 affixOffsetTop,或者通过 "affixHeader": false 关闭固定顶部功能。
问题是:内容被盖住了怎么办?
回答:使用文心输出结果是
如果您在初始化 Amis 渲染器时设置了 affixOffsetTop 并且想要关闭固定顶部功能,但是内容被盖住了,您可以尝试以下方法:
1. 检查 affixOffsetTop 的值是否正确,并且是否存在与其他元素的重叠或冲突。如果有,请尝试调整它。
2. 检查 affixHeader 是否为 false。如果是,请将其设置为 true。
3. 检查页面中是否有其他固定顶部或定位的元素,并且它们的位置是否与您的内容相冲突。如果有,请尝试调整它们的位置或移动它们。
4. 检查您的内容是否过于密集,并且是否无法在页面上居中显示。如果是,请尝试调整您的布局,使其更易于阅读和理解。
如果您仍然无法解决问题,请考虑在代码中添加更多的错误处理和调试信息,以便更好地理解和解决问题。可以看到文心理解了上下文并做了回答,但它还会补充两条上下文里没有的说明,属于幻觉问题。
如何检索到相关段落?在大模型应用时经常见到的方式是基于 embedding 的向量距离搜索,获取文本的 embedding 可以使用文心千帆的 Embedding-V1 接口,也可以用类似下面的代码测试
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('moka-ai/m3e-base')
query_embedding = model.encode('内容被盖住了怎么办')
passage_embedding = model.encode(['CRUD 顶部有重叠遮挡',
'某个操作完如何刷新页面'])
util.dot_score(query_embedding, passage_embedding)
# tensor([[267.7354, 300.3743]]),第一个距离更小所以更相关如果有大量文本段,最好使用专门的向量数据库存储,有专门索引(比如 HNSW)因此性能更好,目前主要有三种类型的向量数据存储:
-
单机内存型,比如 faiss、chroma,如果数据量不大且都是自己的文档,可以直接使用这样的单机向量存储,部署和运维都简单。 -
分布式的向量数据库,比如 Milvus、Weaviate、qdrant,适用于大量文档场景,但分布式部署导致了运维成本高,比如 Milvus 还依赖 etcd、minio、Apache Pulsar 服务。 -
已有服务扩展,可以使用 RedisSearch、pgvector、Elasticsearch、ClickHouse,它们可以直接在现有服务上扩展,避免新增运维成本。
-
LlamaIndex 是自己实现的简单文本解析 -
Langchain 是基于 Unstructured 实现的,而 Unstructured 内部是先转成 HTML 再拆分
图标
可以配置 icon 配置项,实现按钮显示图标
schema: scope="body"
{
"label": "弹框",
"type": "button",
"actionType": "dialog",
"icon": "fa fa-plus",
"dialog": {
"title": "弹框",
"body": "这是个简单的弹框。"
}
}icon 也可以是 url 地址,比如
schema: scope="body"
{
"label": "弹框",
"type": "button",
"actionType": "dialog",
"icon": "https://suda.cdn.bcebos.com/images%2F2021-01%2Fdiamond.svg",
"dialog": {
"title": "弹框",
"body": "这是个简单的弹框。"
}
}我们会从这段文本中它生成 7 段文本来取向量,分别是:
-
行为按钮图标 -
行为按钮,图标可以配置 icon配置项,实现按钮显示图标 -
行为按钮,图标 icon 也可以是 url 地址,比如 -
图标可以配置 icon配置项,实现按钮显示图标 -
图标可以配置 icon配置项 -
实现按钮显示图标
-
让大模型看到完整段落(但需要注意不能超过上下文窗口大小),更容易生成正确答案。 -
这段文本可以通过 hash 地址定位,在生成回答的时候还能附上相关链接,让用户点击文档进一步确认,缓解大模型幻觉问题。
-
无法回答综合性问题,比如「amis 一共有多少个表单组件」,向量搜索只能返回表单相关的段落,根据这些段落无法回答这个问题。 -
相关段落反而可能会干扰大模型,比如搜索「表单如何水平居中」,会找到「当表单在水平模式下时,如果 group 内表单项设置…」这样的段落,如果大模型不够「智能」,可能会被这句话影响,导致输出错误内容,使得有时候还不如直接将向量搜索结果输出给用户。 -
大模型窗口大小限制,amis 文档经常包含较长的代码片段,导致很容易超过窗口限制。 -
向量搜索效果不稳定,有时还不如基于关键词检索,尤其是用户输入很短的问题时,所以最好配合 BM25 等搜索技术来多路召回。 -
「幻觉」问题令人头疼,使用这种方法虽然一开始给人感觉很惊艳,可以进行比较模糊的搜索,但用了几次就会发现大模型输出结果不稳定,最近有个案例是 Mozilla 上线了基于向量搜索和 OpenAI 的 AI 问答机器人,很快就被社区用户吐槽经常瞎说还不如没有。
04
生成数据模型

大模型在爱速搭中的另一个重要应用是生成数据模型,数据模型是爱速搭中表结构定义,是开发应用的第一步,需要根据需求设计表结构,这是一件很费时的事情,比如下面是爱速搭中的示例,对于复杂应用通常会有几十个表,复杂表有十几个字段。
 爱速搭数据模型示例
爱速搭数据模型示例
我们可以让大模型来辅助生成,简化开发成本,比如使用下面的提示词
开发一个 CRM 系统需要哪些表?
以 JSON 数组输出,数组里有两个字段,
一个是表名 `name`,
一个是表描述 `fields`,`fields` 是个数组,包含表里的字段说明
字段说明里以下 key:字段名 `name`、字段中文名 `label`、字段类型 `type`、字段大小 `size`
字段类型 `type` 只能是以下几个值:int, varchar, float, decimal, datetime文心就会输出类似下面的内容
[
{
"name": "customers",
"fields": [
{
"name": "id",
"desc": "客户ID",
"type": "int",
"size": null
},
{
"name": "name",
"desc": "客户姓名",
"type": "varchar",
"size": "255"
},
{
"name": "email",
"desc": "客户电子邮件",
"type": "varchar",
"size": "255"
},
{
"name": "phone",
"desc": "客户电话号码",
"type": "varchar",
"size": "20"
},
... 太长忽略有了这个结构化的输出,我们就能自动生成表结构定义。
想要输出复杂 JSON 就得有办法告诉大模型 JSON 结构,目前我知道的有两种做法:
-
TypeScript 定义,比如 Kor 和 TypeChat(这个项目的作者竟然是 TypeScript 编译器开发者。。) -
JSON Schema,比如 Jsonformer,OpenAI 的函数调用功能也是使用 JSON Schema 方式,可能是专门微调过了,没有训练过代码的其它大模型可能支持不好
输入:开发一个 论坛 系统需要哪些数据库表?
输出:用户表/user、帖子表/post、分类表/category、通知表/notificatoin、分组表/group
输入:开发一个 博客 系统需要哪些数据库表?
输出:文章表/article、分类表/category、标签表/tag、评论表/commont、用户表/user
输入:开发一个 IT管理 系统需要哪些数据库表?
输出:资产表/asset、部门表/department、用户表/user、分类表/catetory、位置表/location、公司表/company
输入:开发一个 {system} 系统需要哪些数据库表?
输出:用户输入「客户关系管理」,文心的输出结果就是
客户表/customer、联系人表/contact、订单表/order、发票表/invoice、合同表/contract、项目表/project、产品表/product、销售表/sales、地区表/region接着进一步生成表里的字段,比如类似下面的提示词
数据库类型有以下几种:int、text、datetime、decimal、float
输入:开发一个 博客 系统的 文章表 需要哪些数据库字段及类型?
输出:id/int、title/text、content/text、publish_date/datetime、tag_id/int
输入:开发一个 教学 系统的 学生表 需要哪些数据库字段及类型?
输出:id/int、name/text、age/int、gender/text、class_id/int
输入:开发一个 {system} 的 {table} 需要哪些数据库字段及类型?
输出:其中的变量分别填入「CRM 系统」和「客户表」后输出结果是
id/int、name/text、age/int、gender/text、contact/text、contact_type/text、status/text、created_at/datetime、updated_at/datetime这样我们拿到了表名及字段信息,然后转成爱速搭内部数据模型的 JSON 接口,就能生成数据模型实体了。
因为所有表的生成完全依赖大模型能力,因此是个很通用的功能,比如输入「招聘」两字,将生成以下表结构
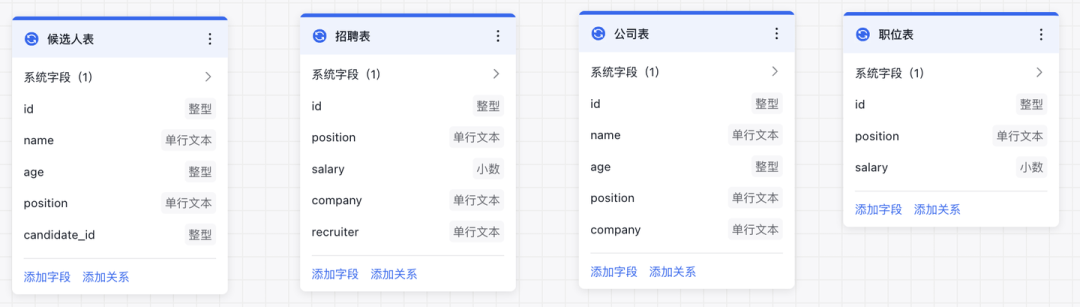
虽然这个结果不算完美,但我们仅仅输入了「招聘」这两个字,能得到这么多结果已经不错了,节省了不少时间,如果输入更多信息,可以得到更好结果。
这个应用场景我们只使用提示词就完成了,是大模型应用中最常见的方式,它的开发成本很低,能支持各种类型的任务。
提示词方面我们主要是用 few-shot,好处是可以支持许多模型,我们试过大部分开源基础模型都可以使用。
除了简单的 few-shot,这两年出现了许多提示词技巧来优化效果,比如:
-
Chain of Thought: 提示词的示例中包含一步步解题过程 -
Self-Consistency: 在 Chain of Thought 基础上生成多个答案,少数服从多数 -
Tree of Thoughts: 每次生成多个结果,每个结果,取其中最好的前几个进一步生成,类似 Beam Search -
Least-to-Most -
第一步,先让大模型将问题拆分成子问题,「To solve xxx, we need to first solve: 」 -
第二步,分别让大模型去解决这些子问题,将子问题的解答放入提示词中,问最开始的问题 -
Generated Knowledge Prompting: 让模型先生成关于这个问题的知识点,再去回答问题 -
Automatic Prompt Engineer: 让模型生成和这个问题类似的问题,然后评估这些问题哪个更好,再去问模型,相当于让大模型先帮忙优化一下提示词
-
性能较慢,许多技巧都需要多次请求大模型,而现在大模型每次请求都需要 5-10 秒,请求次数多会非常慢,用户体验差。 -
这些技巧大多是针对 ChatGPT 的,在开源模型上通常效果不好,需要详细测试,具体细节推荐看 Prompt Engineering Guide。
05
生成页面

除了数据模型,前端页面编辑也是爱速搭的核心功能,因此是大模型应用重点。
从这几年的经验看,生成页面这个功能很容易吸引眼球,比如 2017 年的 pix2code、2018 年的 Sketch2Code、2020 年 GPT-3,虽然仔细想想会发现都 6 年了还没出现成熟的商业产品,但是它们每次都吸引了大量关注,在 GPT-4 的演示上也出现了根据草图生成网页功能,是播放量最高点,尽管仔细一看这个页面就是 20 年前的 HTML 水平
 GPT-4 多模态演示
GPT-4 多模态演示
但在低代码平台中基本上都不会直接使用 HTML,而是使用内部的 JSON DSL 语法,比如爱速搭我们使用的是 amis,因此我们要做的事情是根据用户描述来生成 amis 配置。
如何实现这个功能?一个思路是类似前面数据模型那样构造个 JSON 格式返回需求,让大模型生成,有些零代码平台是这样做的,比如 Framer,它的安全意识真弱,竟然直接由前端构建好 OpenAI 的请求结构,直接暴露了它的所有提示词,我们可以分析一下它
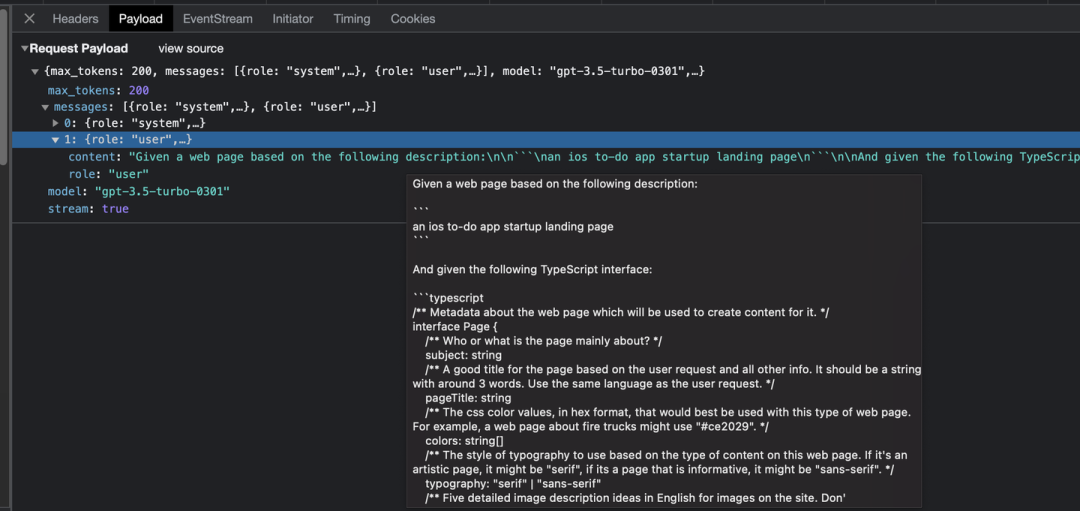 framer 的提示词
framer 的提示词
它的实现方案是通过 TypeScript 定义来指导 GPT 的返回格式及字段要求,提示词是
/** Image keys that are available for use. */
type ImageKey = "single_object" | "sky" | "forest" | "close_up_of_plant" | "silhouette_female"
type Section =
// A heading with four images under it
| { id: "gallery"; galleryTitleMax3Words: string; picture1: ImageKey; picture2: }
// A big heading with a smaller text next to it
| { id: "generic_text_1"; heading: string; paragraph: string }
// A small category/label followed by a big text (a sentence or so)
| { id: "generic_text_2"; labelOrCategory: string; shortSentence: string }
// Title and description, next to it is a list of four items with years
| { id: "text_list"; sectionTitle: string; sectionParagraph: string; listTitle: string; item1Title: string; }
// Has 3 differently priced plans in format $4.99/mo etc
interface Page {
/** Several sections with the content that will appear on the page (top to bottom). */
sections: Section[]
}简单来说就是让大模型根据描述生成页面 sections 列表的 JSON 格式描述,是零代码产品基于大模型生成页面的常规做法。
实际页面生成还是靠零代码平台本身,以我们之前的经验看,只要区块质量足够高,哪怕是做简单规则再随机生成,第一眼效果都会不太差,所以大模型只要比随机好点就行。
但这个方式并不适合爱速搭的 amis,因为 amis 有 130+ 组件,没办法在提示词里全部说明,而且还需要预留至少 1k token 来输出内容。
同时向量检索的方式也不太合适,很容易漏掉关键的语法说明。
因此我们使用了指令微调(SFT)方式。
根据 The Power of Scale for Parameter-Efficient Prompt Tuning 里的测试,微调模型效果远远好于在提示词优化,基于提示词的 GPT-3(1750 亿参数)效果还不如微调的 T5-XXL(110 亿 参数)模型。
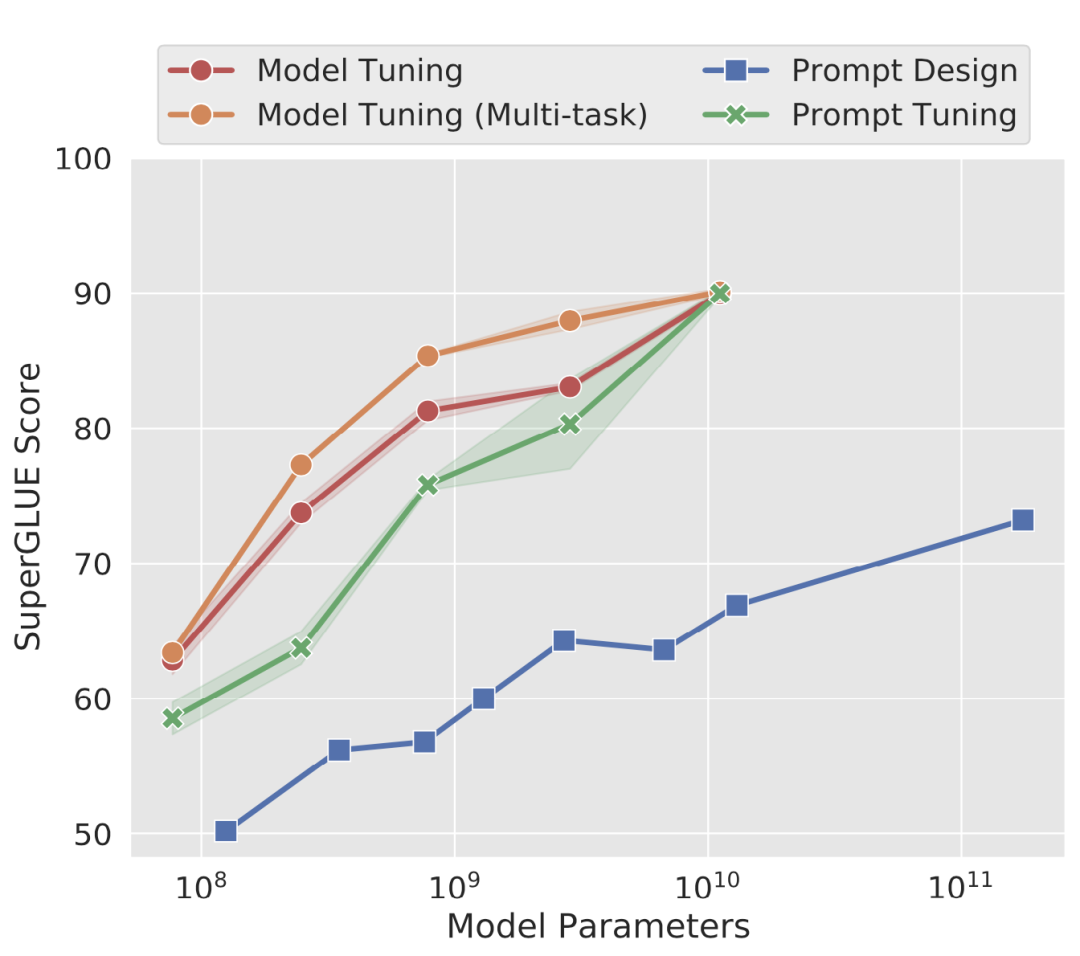 模型微调和提示词设计效果对比
模型微调和提示词设计效果对比
训练数据构造
{
"type": "form",
"title": "表单",
"body": [
{"type": "input-text", "name": "username", "label": "用户名"},
{"type": "input-password", "name": "password", "label": "密码"}
]
}除了人工构造训练数据,我们还用了许多程序化的方式来构造,比如
-
通过程序化排列组合,比如表单项有很多通用配置项,类似必填、尺寸等,每个表单项都会生成一遍,避免了人工重复编写。 -
问题自动扩充,比如同一句话可以有不同说法,通过大模型的方式来扩充类似问题,可以成倍扩充问题数。 -
根据答案反向生成问题,这是参考 Humpback 里的思路,训练一个反向生成问题的模型,然后拿一堆 amis schema 来反向生成问题。
训练目标
def preprocess(
sources: Sequence[str],
targets: Sequence[str],
tokenizer: transformers.PreTrainedTokenizer,
) -> Dict:
"""Preprocess the data by tokenizing."""
examples = [s + t for s, t in zip(sources, targets)]
examples_tokenized, sources_tokenized = [_tokenize_fn(strings, tokenizer) for strings in (examples, sources)]
input_ids = examples_tokenized["input_ids"]
labels = copy.deepcopy(input_ids)
for label, source_len in zip(labels, sources_tokenized["input_ids_lens"]):
label[:source_len] = IGNORE_INDEX
return dict(input_ids=input_ids, labels=labels)这样在反向传播的时候就只有答案参与计算。
微调训练主要有两种方式,一是全参数微调,另一个是高效参数微调(PEFT),全参数微调对显存要求很高,单台 A100 80G 都做不了,因此通常使用的是高效参数微调,目前最常用的方法是 LoRA,它不仅在大语言模型里常用,也是文生图 Stable Diffusion 中的主流微调方法。
因此我们也主要使用 LoRA 进行微调,LoRA 有许多超参数,影响最大的是 target_models,最开始用的是参考 Palatypus 项目里建议的 gate_proj,down_proj,up_proj,结果后来发现还不如常见的 q_proj,k_proj,v_proj,o_proj,而 rank 参数影响不大,8 和 16 几乎没区别。
结果评估
训练完模型后接下来的重要问题是如何评价模型效果?业界常用的方法有:
-
生成时的困惑度(Perplexity),简单来说如果模型输出每个 token 时概率都很高,就代表模型很有信心、效果好,这种方式实现起来最简单,但和业务无关,不一定能反应真实情况。 -
人工打分,比如 ChatbotArena,使用人工匿名打分排序,好处是准确性高,但人力成本很高。 -
客观题评分,就是单选或多选题,结果容易自动检测,比如 C-Eval,是人工整理了各行业考试题,但它和我们使用大模型的场景不一致,我们希望是生成 JSON 而不是解题,另外它本身就自带了大量训练问题,只要有厂商将测试题拿去预训练多刷几次就能提高分数,所以后来出现的模型如果在这个评测上分数过高反而很可疑,目前榜单上有大量超过 ChatGPT 的国产模型,然而在实际应用场景都不如 ChatGPT。 -
结果相似度,比如编辑距离、BLEU 和 GOUGE,主要用于机器翻译或摘要,BLEU 是相同词汇在正确文本中出现的比例,注重准确率,GOUGE 是计算相同词汇在生成文本中的比例,注重召回。 -
pass@k,某些领域可以方便检查结果,比如生成代码可以用单元测试进行检查,这时就能通过生成多次看是否能有一次成功。
-
amis 是深层 JSON 结构,如果结构不对,即便所有相关单词都出现也不行 -
JSON 有严格的结构,多了个特殊字符就没法解析,这时无论正确出现多少单词都没用
-
如果有 8 个的键值都正确就是 8/11 -
如果值不同,值要求是固定值比如 type 必须是某个值,不完全匹配就是 0 分(甚至后面考虑减分,因为这个属性太重要了) -
如果值不不同,值不需要完全匹配,比如 label 这种,就用 BLEU 1-gram 算个分数作为这个属性的得分,比如 0.7,那加上前面完全匹配的就是 8.7/11。不过对于 name 这种属性,其实 username 和 user_name 都没错,但按 BLEU 算就是 0 分了,所以某些值允许不同。 -
整个过程是递归,比如 {“body”: [{“type”: “input-text”}]} 和 {“child”: [{“type”: “input-text”}]},由于 child 错误,导致它的子元素正确也没用,计算结果是 0 分。
关于继续预训练
产品集成使用
 爱速搭中的智能助手对话框
爱速搭中的智能助手对话框
06
自然语言查询数据

除了生成数据模型和页面,在爱速搭中我们还做了另一个基于大模型的重要功能:自然语言查询数据。
自然语言查询数据是大模型热门应用之一,实现就能让不了解 SQL 的用户也能查询数据,有很广的应用场景。
目前业界在这方面也做了许多研究,比如在 Spider 评测集上前 6 全是基于 GPT 的实现,最高分数能到 86.6。
我们最开始的想法是当成个翻译问题,使用前面生成页面的方案,只要搜集大量文本 SQL 对,对模型进行微调就好了,然而真正做的时候才发现这个问题远比翻译难,比如下面这些问题:
-
中文和表名不匹配,表名基本都是英文,甚至可能是简写,如果用户都不知道表名是什么,极有可能问个不相关的中文名,导致查询错误,另外字段也有这个问题。 -
问题和值格式不一致,典型的场景是类似枚举类的字段,比如我要代付款的用户,但数据库里存的可能是 0/1/2/3 这样的整数,需要有信息让大模型知道这些字段如何对应。 -
对值的要求严格,比如查询「北京」的用户,数据库可能的值是「北京市」,如果用「北京」进行等于比较肯定没结果。 -
值有隐形知识,比如对于金额类型,数据库里可能存的是分为单位的整数,要查询一块钱应该查 100 而不是 1。 -
值可能要做二次处理,比如数据库里存日期 datetime 类型,要查询「2023 年」的数据,这时查询需要加函数,变成类似 EXTRACT (YEAR FROM xx) = 2023 的语句。 -
很多时候需要猜测字段,比如「查询苹果手机的总销量」,而不是问「查询商品标题包含苹果手机的总销量」,这时需要根据值推测查询哪个字段,而在表结构定义里并没有值信息,导致难以正确判断。 -
有些值是动态的,比如「查询昨天的销量」,这个值需要根据提问时间动态确定,在训练数据中没法写死某个具体值,如果是用数据库函数实现又涉及到方言问题,比如 MySQL 是 DATE_SUB (CURDATE (), INTERVAL 1 DAY);甚至有可能涉及到业务信息,比如「查询我卖出去的总金额」,这里的「我」取决于当前用户。 -
表里有隐性信息,比如软删除功能,所有查询都必须先过滤一下,不然结果肯定是错的。 -
关联查询,对于有 JOIN 的场景,需要识别表之间的关联关系,通常在表结构里没有表现,因为很多公司禁止设置外键约束,这时就需要自动识别关联关系。 -
需要一定推理能力,比如查找所有成年用户,数据库里只有生日,得用当前时间减去生日再判断大于 18。 -
有些功能没法通过单个 SQL 语句实现,这个问题最麻烦,比如「查询班级和对应的学生,只返回 10 个班级」,需要至少查询两次或者 N+1 次。 -
数据库方言问题,数据库有方言问题,尤其是 LIMIT 及函数调用,如果只训练某种方言,会导致生成的 SQL 在其它数据库下无法运行,限制了使用范围。 -
容错性低,前面的生成页面功能如果某个组件生成错了影响不大,而生成 SQL 只要有一点错误,查询结果就肯定是错的。
-
是否默认加 limit,用户基本不会说「只返回前 10 条」,如果数据量非常大,一个查询数据库就卡死了。 -
安全问题,参考这篇分析,SQL 语法非常复杂,大部分表达式都支持无限层级嵌套,要对它进行安全分析相当困难,需要实现完整 SQL 语法解析和上下文语义匹配,工作量很大,所以基本目前都是直接执行 SQL 而没做安全检查,比如 Langchain 里的 SQL 功能,这导致非常容易实现 SQL 注入,另外除了注入,还有表权限也都全绕过了,比如可以直接说「查询用户表里用户名为 xx 的 password 字段」。 -
窗口大小限制,一个简单的表结构描述都要 100 token,相对复杂点的表,比如有 50 个字段就超过 2000 token 了,而现在大部分大模型的上下文窗口只有 2K-4K,导致有时候甚至只能放一张表结构定义,没法做关联查询了。
因此在爱速搭中,我们并没有使用 NL2SQL 方案,而是 NL2JSONQL,这个 JSONQL 是爱速搭自研的数据查询语法。
具体来说是通过这两方面解决:
-
通过数据模型来补充缺失的信息 -
数据模型定义可以添加表和字段的中文名,这样大模型能更好匹配到字段。 -
枚举类型可以设置枚举值,大模型能通过这个信息知道要去查什么值,更容易生成正确的过滤条件。 -
可以定义关联字段,设置了关联字段后,因此只需要简单的 book.auther.name = “作者名” 就能自动做关联查询,这个关联查询是可以无限层级的,无需知道表之间如何关联,因此生成的内容很简单,模型无需输出 JOIN,因此简化了生成难度。 -
自动支持软删除,可以直接在模型上定义,查询时会自动生成查询条件。 -
查询引擎自动适配,简化程序 -
自动适配日期查询,比如查询 2023 年,直接使用 create_date = 2023 就行,无需使用函数转换,查询引擎会自动识别出这种场景,自动转成 EXTRACT (YEAR FROM create_date) = 2023 (根据数据库方言转成不同函数)查询,同样还有年月等场景。 -
自动适配方言,大模型输出结果是和方言无关的 JSON,由查询引擎自动转成数据库方言进行查询,甚至支持 NoSQL,比如转成 MongoDB 命令来查询 MongoDB 数据库。 -
自动识别枚举值,如果发现查的是名称,比如 订单状态 = “待付款”,引擎发现这是枚举的文本,就自动改成查询 订单状态 = “0”。 -
容错机制,比如查询了模型定义里不存在的字段,引擎会自动忽略,避免报错。
`status` int(1) NULL DEFAULT NULL,在爱速搭中可以将这个字段指定为枚举类型,然后配置它每个值对应的内容,如下图所示
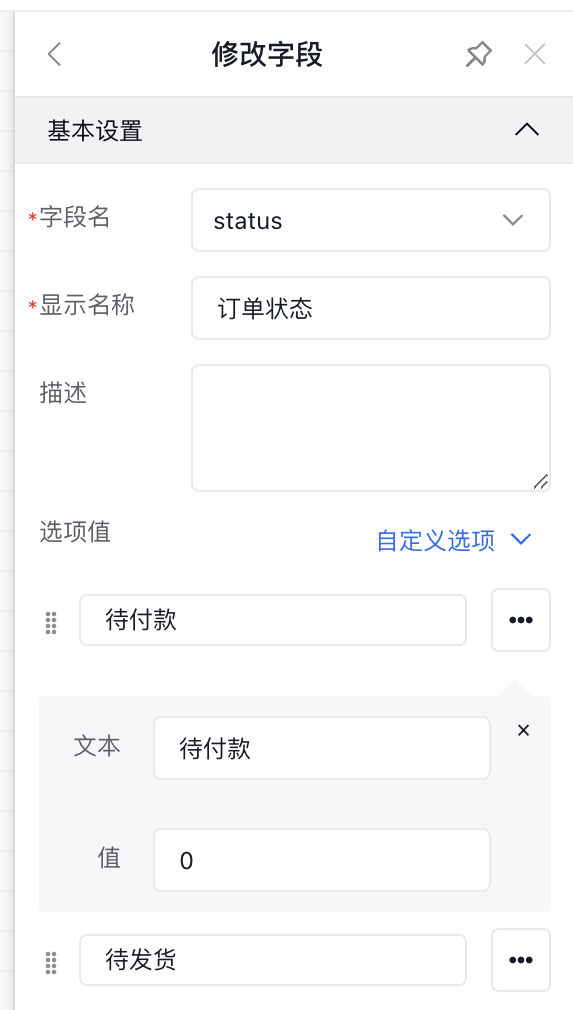 爱速搭数据模型里对字段的定义配置
爱速搭数据模型里对字段的定义配置
需要注意 JSONQL 并不是极简化的 DSL,它几乎包含了所有开发会用到的 SQL 语句,包括 JOIN、子查询、Having、CASE 等子句,我们测试过可以覆盖 TPC-DS 和 TPC-H 里的语句,因此这个方案的上限很高,只需补充更多复杂场景的训练数据,就能实现其它 NL2SQL 方案能覆盖的所有场景,前面的简化主要是为了提升大模型准确率。
同时使用 JSONQL 引擎还自动解决了安全问题:
-
自动权限过滤,设置了行列权限后,查询引擎会自动加上行过滤和列删除,无法查询自己没权限看到的内容。 -
SQL 语句白名单,虽然 JSONQL 引擎能覆盖绝大部分 SQL 功能,但在实现上是白名单机制,严格限制了可以调用哪些函数、支持哪些 SQL 子句等,类似 TRUNCATE 之类的危险子句不可能输出,因为引擎就没实现,也不用担心某个小众数据库可能存在的高风险函数,因为只有白名单中的函数才能输出。
a > b and (c < 1 or d > 2) 这样的过滤要怎么通过自然语言描述?因此只支持「且」和「或」两种情况。07
生成代码

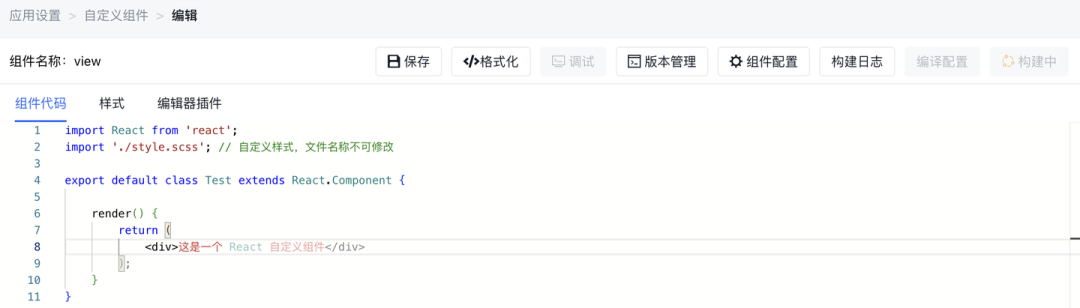 爱速搭中的自定义前端组件功能
爱速搭中的自定义前端组件功能
如果能减低这部分代码编写成本能提升应用开发效率,因此我们也探索了大模型在这方面的应用。
目前大模型在代码领域有许多应用,包括:
-
根据自然语言生成代码 -
根据代码生成注释 -
解释代码 -
根据代码生成测试代码 -
对代码进行补全 -
对中间代码进行补全
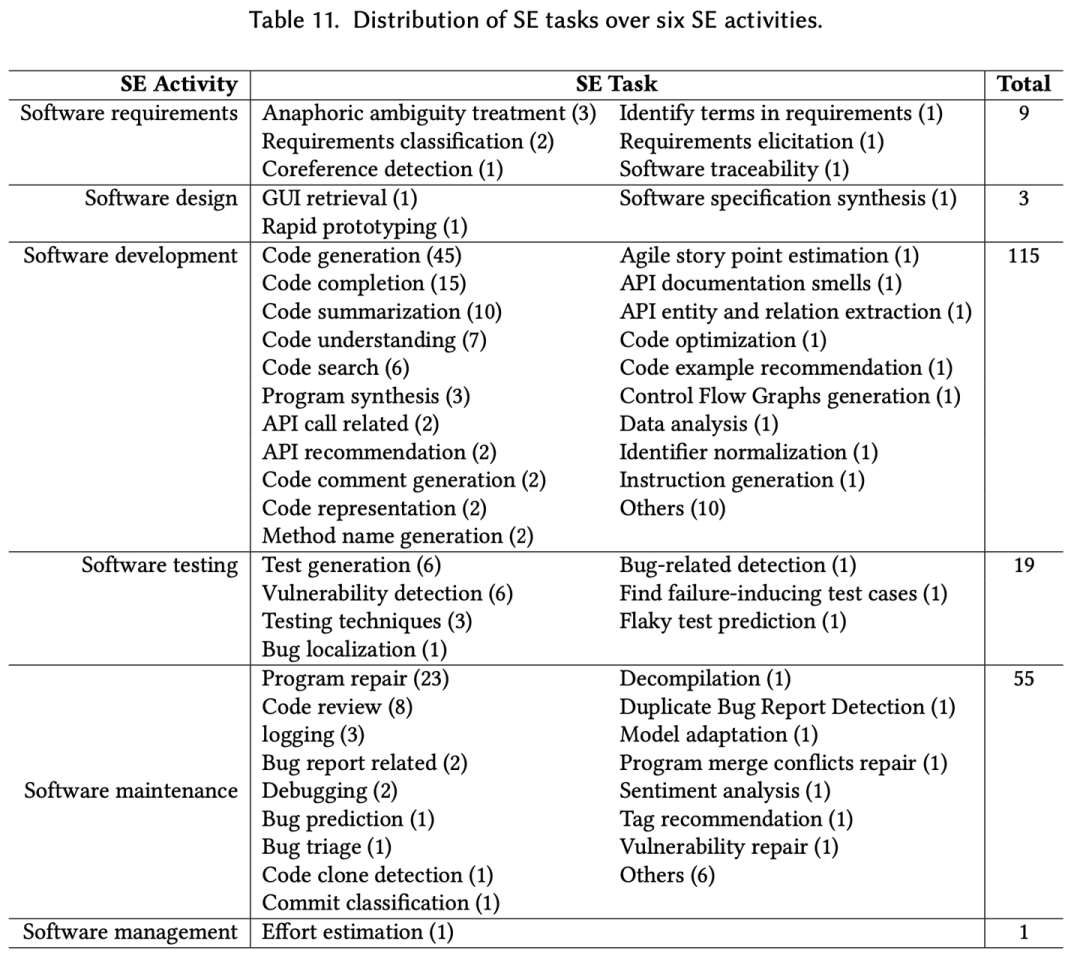 Large Language Models for Software Engineering: A Systematic Literature Review
Large Language Models for Software Engineering: A Systematic Literature Review
从训练角度看,其中最特殊的是对中间代码进行补全,这是在代码开发辅助场景中最常见的情况,在写代码时我们通常是在中间部分编写,比如下面这个示例
if (a > b) {
// 光标位置
}如果按照一般的续写逻辑,模型很可能会补上后面那个花括号(}),多出的这个花括号会导致语法报错,因此这种场景需要特殊的训练方法。
怎么做呢?说起来也简单,可以参考 OpenAI 里的做法,就是随机把代码分成 3 份,然后调整一下顺序,将中间部分放到后面,类似如下转换(实际中间会加些特殊 token 方便大模型区分)
document → (prefix, middle, suffix) → (prefix, suffix, middle)这样就变成和其它任务一样的自回归续写逻辑了。
类似 Copilot 这样的代码辅助工具可以明显提升编码效率,我平时写代码可能有 20% 是生成的,因为很多代码都有规律,比如 switch 里的 case 通常和前面有关。
这类产品的原理决定了必须将当前编写的代码上传到服务器,具体细节可以看逆向 Copilot 代码的分析,因此对于保密性较高的代码不应该使用 Copilot,而是最好使用开源模型或类似百度 Comate 这种支持私有部署的模型。
大模型刚出来的时表现出了不错的代码编写能力,使得有人预测它将取代程序员,但这是不可能的,我们可以从实现原理分析,要实现这样功能你需要一段文本和一段对应的代码来训练,比如 Copilot 用的是函数注释及对应的实现,最新号称效果更好的 StarCoder 还用了 github issue、pr 说明以及 git 提交里的 message,算是能想到的都用上了,可以看出有几个问题:
-
有注释的代码占比很少,如果再过滤中文就更少了,所以 ERNIE-Code 只好使用双向语言训练来提升中文效果 -
真正优秀的注释不是解释做了啥,而是解释为什么这样做,因为代码本身写得好就是解释 -
注释是函数级别的,所以模型就只能做一件小事情,对于需要大量函数组合的复杂事情无能为力,因此没法生成项目级代码。 -
现阶段语言模型都有窗口限制,比如 GPT 是 4K,大概对应 3-4 百行代码,做不了什么事情。 -
代码最佳实践一直在变化,比如 Vue 正在逐渐转向 3,但现有代码里肯定大量是 Vue 2 的写法,导致对于变化较快的领域,生成的代码容易过时。
曾经有个报到说 ChatGPT 通过了 Google 的面试题,说明什么呢?大模型可以取代研发?可能只能说明 Google 的面试题答案在网上到处都是。
现在很多人测试大模型写代码能力都是用排序、贪吃蛇什么的,这些经典老问题大模型训练数据里见过无数次了,很难用来真正判断大模型写代码能力。
现阶段大模型对于复杂的代码基本无能为力,比如我几个月前写过的一段代码「使用 TypeScript 语言实现将 OOXML 的 DrawingML 格式转成 SVG 格式」,这个问题在网上没有现成答案可以抄,因此我试过没有任何大模型能正确实现。
整体下来我们觉得大模型虽然能生成代码,但效果不够好,所以这个功能目前只作为辅助,使用提示词来实现,没有进行特殊优化。
08
对平台进行操作

使用大模型提升效率还有个场景是让大模型作为助手来调用外部工具执行操作。
在爱速搭低代码平台中,为了避免界面太乱,将一些不太常用的功能放在了很深的目录里,用户往往找不到,这时就能借助大模型来识别用户需求,转成对应操作。
这个想法很早之前就出现过,如果你和我一样用了 20 多年电脑,应该会知道 Office 2000 里出现过一个长得像回形针的工具。
 Office 里的 Clippy
Office 里的 Clippy
实现这种场景的方案主要有两种,一种是转成某个 API 或工具调用,另一种是多个 API 组合,比如最近很火的 Office Copilot,它是如何实现的呢?虽然官方并没有透露,但我找到了这篇相关论文,是微软员工写的,很可能就是类似方案。
它的做法是设计了一套简单的语言,内置一些函数调用,然后使用检索增强(RAG)的方式找到相关函数,动态生成带有相关例子的提示词,最终使用 GTP 3.5 来生成,比如下面是这个 DSL 语言的简单示例,大部分是调用某个函数
# Formats the text in textRanges with a set of formatting properties.
format_text(textRanges=textRanges, bold=true, fontName="Times New Roman",
horizontalAlignment="Left", color="teal", italic=true, underline="Wavy")
# Deletes shapes provided to the shapes parameter.
delete_shapes(shapes=shapes)这种方式虽然实现起来简单,但很考验模型的推理能力,但有人分析过 GPT-4 不具备推理能力,各种开源模型就更差了,所以实际落地效果还待评估。
因此我们转向了相对更简单的单功能识别,也就是识别单个命令并调用,这个方案要简单得多,可以通过前面微调的方式训练。
需要注意并不是所有功能都适合用这种方式实现,上一代智能助理就是个教训,大部分场景下 GUI 的使用体验更好,比如用自然语言去删某个组件就远不如鼠标右键点删除。
另外在大模型调用外部工具方面目前还有个很热门的应用是 AI 智能体(agent),相当于将大模型当个有智能的人一样去完成各种任务,它能做出非常吸引眼球的应用,比如现象级的 Auto-GPT 项目,但前面提到过目前最强的 GPT-4 也不具备推理能力,因此这些应用恐怕永远都走不出 DEMO,需要等待更强的大模型出现。
整体小结

你可能会发现大部分功能的实现方案都是很类似,就是准备训练数据然后对模型进行微调,这也被称为以数据为中心的 AI 开发,大部分时间都花在折腾数据上,同时我们还尽可能结合了爱速搭原本的低代码功能,比如 amis 和 JSONQL,通过低代码来简化输出,减少大模型幻觉问题。
这样做有几点好处:
-
不受窗口大小限制。 -
不需要提示词技巧。 -
效果比提示词技巧好得多。 -
支持私有部署,我们大部分客户部署环境甚至都没法连公网。 -
运行成本低,即使用 7B 参数量的模型效果也不太差,可以 8 bit 量化后在 CPU 上运行。 -
更加可控,遇到失败案例时可以加相关训练数据来优化。
09
落地过程中存在的问题

最后我们讨论一下大模型在落地和应用过程中都存在哪些问题。
幻觉问题
幻觉是阻碍大模型应用的最大问题,因为许多场景对错误容忍度低,但我认为这个问题无法解决,理由如下:
-
自然语言天生的不确定性,大模型唯一接口是自然语言,这是它最大优点,也是最大缺陷,语言里的词汇只是「指代」,是「指向月亮的手指」,各种词汇都是抽象化的概念,正所谓「知者不言,言者不知」,语言没法描述本质。 -
一句话只要稍微改几个字,意思就可能和原文不同,因此要解决幻觉就只能输出原文。 -
而大模型无法输出原文,输出原文意味着大模型训练失败,变成数据库了,没有抽取出文本里的重要特征。 -
就更别说原始文本里就有大量相互矛盾的描述,没有什么东西是完全「正确」的,「历史就是任人打扮的小姑娘」。
硬件成本
-
赚钱的场景,也就是工作中使用,比如编程辅助、设计绘图、创意文案、公文编写等,对幻觉容忍度高,是目前大模型最火的应用场景。 -
教育场景,在学生中使用,这也是目前大模型主要场景,根据 similarweb 的流量分析,ChatGPT 在 6-7 月份 18-24 岁用户比例明显下降,这个年龄段有不少人还是学生,但这个场景对幻觉问题容忍度不太高,所以不完全适合。 -
竞品调研和模型训练。 -
不可描述的产品。
使用成本
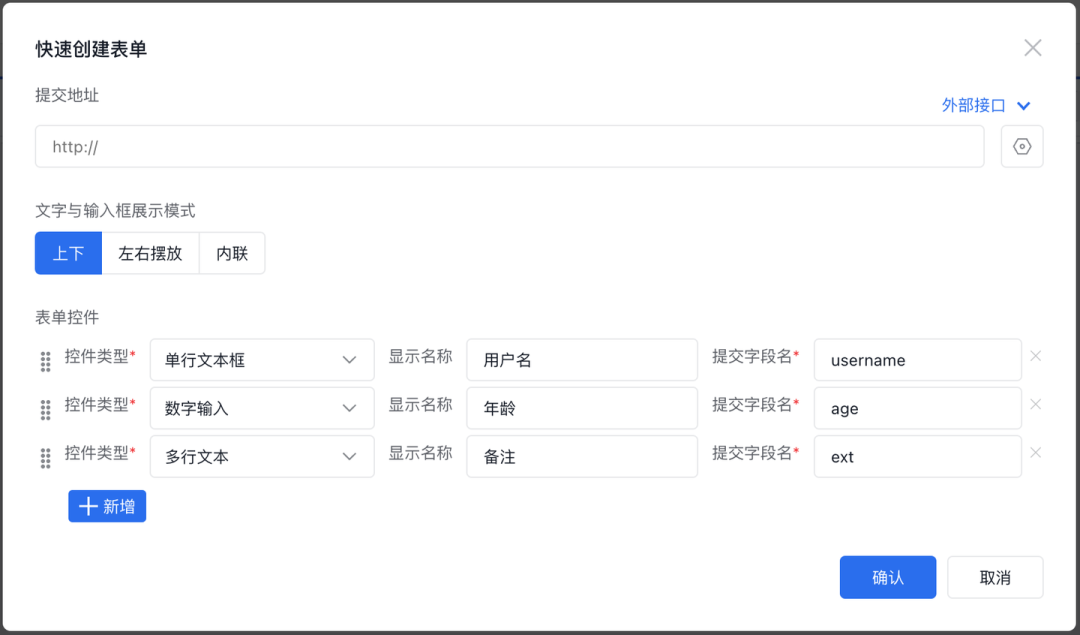 爱速搭的快速创建表单功能
爱速搭的快速创建表单功能
而对于像我这样的熟练工甚至连可视化都不用,主要使用源码模式直接写 JSON
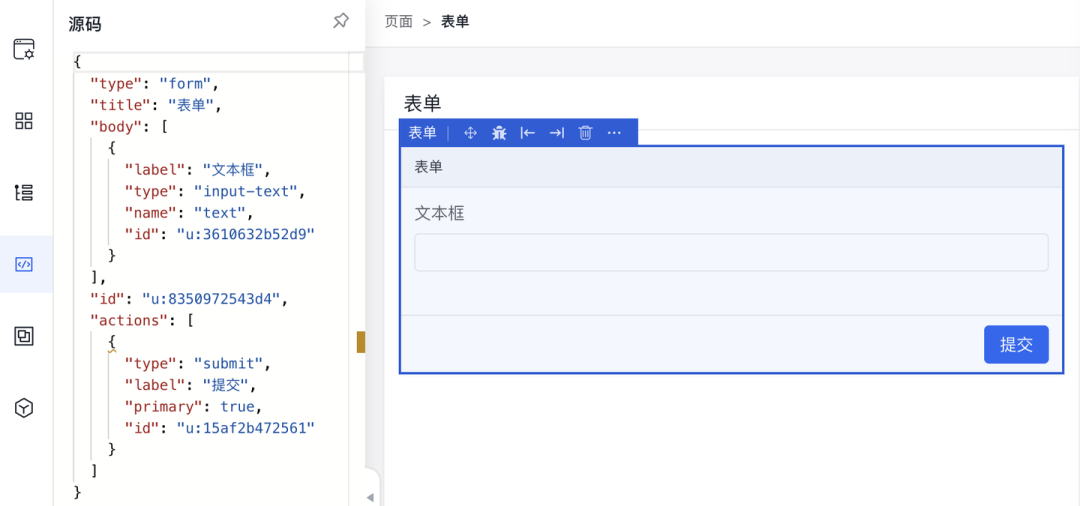 amis 的「源码」编辑模式
amis 的「源码」编辑模式
用户虽然一开始都是小白,但不会永远停留在小白阶段,因此对于自然语言生成页面功能,我们的主要定位是方便不熟悉的用户上手,高级功能还是得靠平台本身。
窗口大小限制
大模型应用过程中最常见问题是窗口大小限制,目前大部分是限制 2K-4K,这是在训练时决定的,并不好扩展,主要是两方面原因:
-
训练成本高,计算量是长度的平方,因此现在很多超过 4k 窗口的模型不得不使用多阶段训练 -
很难找到太长的文本,有人分析过 Github 和 CommonCrawl 里的代码和网页,发现 80% 长度小于 2k,而没训练过长文本就很难生成好,这也叫长度外推性问题。
安全问题
合规问题
– END –
报告下载

大佬观点


