








在这个由数据驱动和智能算法重塑世界的时代,人工智能技术正以前所未有的速度推动着各行各业的创新,智能化编程领域尤其成为了技术革新的前沿阵地。在这场技术变革的浪潮中,国产大模型aiXcoder 7B引起了我们的极大关注。
据悉,北京大学软件工程研究所(简称:北大软工所)早在10年前就已经开始在基于深度学习的代码理解与生成领域布局,旨在填补国内智能化编程领域的空缺,并在国际科研领域展现了来自中国的创新力量。
4月9日,由北大软工所aiXcoder团队开源的7B代码大模型,不仅是对国内软件企业智能化升级的又一次强助力,更是在全球AIGC技术的竞争大潮中,再次展现国产创新的引领作用。
01
模型直观性能对比:高效代码生成补全+项目级代码理解
大型语言模型(LLMs)的性能通常通过准确性、效率、以及对复杂问题的理解能力来评估。对于代码生成和补全任务,评估指标包括但不限于代码的准确性、逻辑完整性,以及模型在处理多文件和大规模项目时的表现。这些性能指标反映了模型是否能够理解和生成符合人类开发者期望的代码,是否能够跨多文件理解项目的全局逻辑,以及是否能在真实的开发环境中高效地辅助代码编写。
实际测验下来看,aiXcoder 7B Base版模型在HumanEval、MBPP、MultiPL-E等测评集的比较结果,超越了同参数量级开源模型,表现十分给力!
1、代码生成表现
多语言支持和适应性:aiXcoder-7B模型在多语言代码生成评测集MultiPL-E中的卓越表现,彰显了其广泛的语言支持能力。通过深入学习和理解18种不同编程语言的语法规则和编程惯例,aiXcoder-7B能够在各种语言间灵活转换,生成符合语言特性的高质量代码。这一能力对于多语言软件项目和跨语言开发环境尤其重要,能够显著提升开发者在不同编程环境下的工作效率。

精确性和问题解决能力:通过HumanEval和MBPP评测集的测试,aiXcoder-7B展现了其在解决编程问题方面的高精确性。这些评测集覆盖了从基础到高级的编程问题,模型能够准确理解问题需求,生成逻辑严密、语法正确的代码解决方案。特别是在处理复杂问题时,模型能够展现出其深度学习和理解编程任务的能力,为开发者提供切实可行的编码帮助。
2、项目级代码理解能力
项目全局逻辑理解:在跨多文件理解方面,aiXcoder-7B通过CrossCodeEval评测集证明了其在项目级代码理解上的优势。该评测集专门设计用来测试模型在处理涉及多文件交互的复杂项目时的表现。aiXcoder-7B通过精确捕捉跨文件间的依赖关系和逻辑流,展现了其在维护大型项目全局逻辑一致性上的高效能力。这对于确保大型软件项目的高质量和稳定性至关重要,尤其是在今天快速迭代的软件开发过程中。

高效的代码补全与自适应性:aiXcoder-7B模型不仅能够在广泛的开发场景中提供准确的代码补全,而且通过aiXcoder Bench展现了其在适应多样化代码补全需求上的灵活性。该模型能够根据开发者当前的代码上下文,智能判断并补全缺失的代码块,无论是完整的方法块、条件判断块还是异常处理块,都能高效生成,大幅提高了编码的效率和质量。此外,模型倾向于使用更短的代码实现功能,这种策略不仅提升了代码的简洁性,也减少了潜在的bug风险。
通过这些深入的技术分析和评测结果,aiXcoder-7B模型的独特优势在代码生成和项目级代码理解方面得以体现。它不仅能够支持多语言环境下的高质量代码生成,还能够理解和维护大型软件项目的全局逻辑,有效提升软件开发过程的效率和质量。
02
高质量数据集与特殊训练方法,代码生成领域的佼佼者
在如今的技术疆界,大型语言模型(LLMs)展示了各自独特的魅力和能力。例如,OpenAI的GPT系列以其卓越的通用性和强大的文本生成能力而受到赞誉,而GitHub Copilot则专注于利用GPT-3为开发者提供编码建议和自动补全功能,极大地提升了软件开发的效率。每个模型都精心优化,以适应特定的任务——从语言理解到代码生成,再到自然语言处理。它们之间的差异体现在处理特定任务的能力、训练数据的质量与规模,以及对特定编程语言特性的支持上。在这些方面,aiXcoder 7B Base版模型巧妙地构建了自己的护城河。
首先,aiXcoder 7B Base版模型利用了1.2T Unique Tokens的高质量训练数据集,这不仅覆盖了多种主流编程语言,还通过详细的语法分析和静态分析,排除了163种bug和197种缺陷。这种对数据集质量的严格控制,为模型提供了一个坚实的学习基础,使得aiXcoder 7B能够更准确地理解和生成代码,显示出其在处理和理解复杂代码结构上的先进能力。
在训练方法方面,aiXcoder 7B Base版模型采用了结合代码抽象语法树结构的预训练任务,这一点增强了模型对代码逻辑的理解能力。此外,通过利用代码Calling Graph构建多文件之间的相互注意力关系,模型显著提高了在跨文件代码逻辑处理方面的能力。这种对代码特性的深入挖掘和利用,使得aiXcoder 7B在真实开发场景下的代码补全效果达到了优秀水平,特别是在需要跨多文件理解和生成代码的场景中表现突出。
模型还支持32K的预训练序列长度,并可在推理时扩展至256K,这一特性大大增强了模型处理大规模代码项目的能力。这种灵活性和扩展性的设计,确保了aiXcoder 7B Base版模型能够适应各种复杂的软件工程任务,体现了模型的技术优势。
03
实战应用中的卓越表现:高效赋能软件开发全链路
通过上述内容,我们已经了解了aiXcoder 7B Base版模型的卓越性能。那么它在软件开发全链路中都有着哪些实际应用表现呢?
在前端开发领域,aiXcoder 7B Base版模型利用其对代码逻辑和结构的深入理解,通过简单的注释即可生成完整的网页代码。这一过程体现了模型在解析自然语言描述到生成对应HTML、CSS和JavaScript代码方面的能力。对于开发者而言,这意味着可以更快地将设计原型转换成可交互的网页,提高开发效率同时降低手动编码的需求。
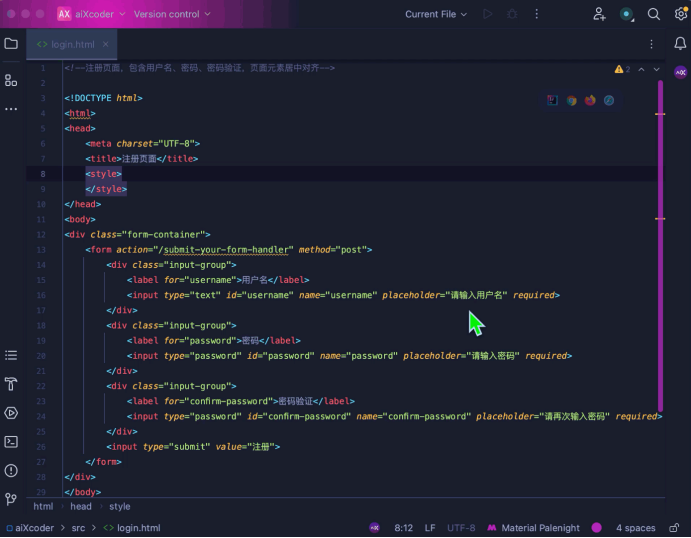
对于后端开发,aiXcoder 7B Base版模型同样显示了其在理解和自动生成HTTP请求处理方法和构建正则表达式等后端逻辑的能力。这些功能的自动化生成不仅加速了后端开发过程,还减少了因手动编码导致的错误,确保了后端逻辑的准确性和稳定性。
在算法开发方面,模型的应用更是展示了其高级问题解决和代码生成的能力。无论是深度学习算法还是基础的数据结构相关算法,aiXcoder 7B Base版都能提供有效的代码生成支持。特别是在面对leetcode等平台上标为hard的高难度算法题目时,模型不仅能够提出解决方案,还能自动生成解决问题的代码,这对于提升算法开发效率和质量具有重要意义。
可见,aiXcoder 7B Base版真正能够理解开发者的需求,以及在实际开发过程中的复杂项目结构,并提供最优雅的解决策略。
04
十年磨一剑,打造企业级软件开发的全方位解决方案
在探索高效、智能化的软件开发新境界时,aiXcoder团队已经积极奔走于技术前沿。自2013年起,他们以深度学习为驱动,对代码分析的深耕研究,让他们在代码大模型的赛道上遥遥领先。经过不懈努力,aiXcoder团队不仅成功为金融、证券、保险等多个行业客户量身打造了个性化的解决方案,通过私有化部署、个性化训练、以及定制化开发,极大地提升了客户的软件开发流程效率。特别地,针对国产硬件和AI芯片的深度适配,更是为国内企业的多样化需求提供了广泛的选择与灵活性。
私有化部署的优化:
在私有化部署方面,aiXcoder 7B Base版模型充分考虑到企业的成本效益,支持低成本且高效能的私有化部署方案,极大地降低了企业使用大型语言模型的门槛。通过对部署文件的严格安全扫描,aiXcoder进一步确保企业的内部环境安全,有效防范了病毒和安全漏洞的威胁。
个性化训练:
在个性化训练方面,aiXcoder通过构建专属于企业的训练数据集,综合企业的历史代码特征和员工的编码习惯,打造出真正符合企业实际开发场景的大模型解决方案。这一策略不仅提升了模型的应用效果,也极大地优化了企业的软件开发流程。
定制化开发服务:
对于定制化开发服务,aiXcoder深度挖掘企业的个性化需求,提供量身定制的开发服务,使得aiXcoder 7B Base版模型不仅在技术层面达到了业界领先,也在服务层面满足了企业在不同业务场景下的具体需求。
国产需求的深度适配:
特别值得一提的是,aiXcoder对国产硬件和AI芯片的支持,这不仅显示了aiXcoder团队对国内市场的深度理解,也展现了其在技术适配上的高度灵活性。无论是国产硬件还是国际知名品牌,aiXcoder都能提供最优的性能保障。
全面的服务能力:
aiXcoder的服务能力不限于上述方面。他们能够迅速完成客户的私有化部署需求,提供专业的现场联调测试服务,确保模型在企业自有的软硬件环境中顺畅运行,从而获得了高客户满意度和信任度。
随着aiXcoder 7B Base版模型的推出和应用,企业的软件开发正在迈向更加高效、智能化的新时代。aiXcoder的这一系列个性化解决方案与服务,正是他们在企业级软件开发领域中独树一帜的核心竞争力,不仅赋能了企业客户,更推动了整个行业的技术进步与智能化转型!
aiXcoder-7B 开源链接:
https://github.com/aixcoder-plugin/aiXcoder-7B
https://gitee.com/aixcoder-model/aixcoder-7b
https://www.gitlink.org.cn/aixcoder/aixcoder-7b-model
https://wisemodel.cn/codes/aiXcoder/aiXcoder-7b


